1.简介
png图片格式采用了一种很灵活的编码设计,支持多种编码方式来展示一张图片:灰度图片、索引彩色图像、真彩色图像、带α通道数据的灰度图像、带α通道数据的真彩色图像。因为png的编码方式灵活,使得其压缩的发挥空间非常大。
2.几种编码方式的说明
注意:这里的一个通道并不等同于1个字节或2个字节,因为png IDAT块的编码单位是bit而不是byte,具体一个通道占用的位数是靠bit depth来决定的
a.灰度图片
灰度图片一般是用来生成我们常见的黑白照片,bit depth可选值为1、 2、 4、 8、16,其一个像素点用一个通道来表示(0~255)或(0~65535),因此这种图片的大小往往非常小
b.索引彩色图像
索引彩色图像很有意思,它可以和真彩色图像一样拥有表达彩色图片的能力,但是一张索引彩色图像上最多只有256种颜色,每种颜色用三个字节(RGB,0~255)表示。它的bit depth可选值为1、 2、4、8,它有一个调色板区域,用来记录索引颜色的值,然后像素点数据区域用一个通道(0~255)来表示调色板区域记录的颜色索引。所以对于色彩不多的图片来说,采用索引彩色来编码是很适合的。
c.真彩色图像
真彩色图像最好理解,它的bit depth为8或16,它的每个像素点都用3个字节(3个通道)来表示,分别为R(0~255),G(0~255),B(0~255),可以表达256256256=16777216种颜色,或者使用6个字节(3个通道)来表示,分别为R(0~65535),G(0~65535),B(0~65535),可以表达655356553565535种颜色。
d.带α通道数据的灰度图像
就是在灰度图片上增加了α通道,共2个通道,支持透明(0~255)或者(0~65535),但是它的bit depth为8或16,因此这种编码方式一个像素点是2个字节或4个字节
e.带α通道数据的真彩色图像
就是在真彩色图像上增加了α通道,同四个通道,支持透明(0~255)或者(0~65535),它的bit depth为8或16,因此这种编码方式一个像素点是4个字节或8个字节
3.png图片具体编码说明
png图片的编码一般如下:header,chunk,chunk,chunk….chunk。
header代表png图片的头,png文件头一般都是由固定的8个字节组成
89 50 4E 47 OD 0A 1A 0A
图片软件可以通过这8个字节来判断这个文件是不是png格式。
chunk代表png图片的数据块,数据块是有不同的类型的,记录了不同的信息。一张png图片可能包含多个数据块。
数据块的类型如下(关键部分高亮显示):
PNG文件格式中的数据块(表1.1)
| 数据块符号 |
数据块名称 |
多数据块 |
可选否 |
位置限制 |
IHDR |
文件头数据块 |
否 |
否 |
第一块 |
| cHRM |
基色和白色点数据块 |
否 |
是 |
在PLTE和IDAT之前 |
| gAMA |
图像γ数据块 |
否 |
是 |
在PLTE和IDAT之前 |
| sBIT |
样本有效位数据块 |
否 |
是 |
在PLTE和IDAT之前 |
PLTE |
调色板数据块 |
否 |
是 |
在IDAT之前 |
| bKGD |
背景颜色数据块 |
否 |
是 |
在PLTE之后IDAT之前 |
| hIST |
图像直方图数据块 |
否 |
是 |
在PLTE之后IDAT之前 |
| tRNS |
图像透明数据块 |
否 |
是 |
在PLTE之后IDAT之前 |
| oFFs |
(专用公共数据块) |
否 |
是 |
在IDAT之前 |
| pHYs |
物理像素尺寸数据块 |
否 |
是 |
在IDAT之前 |
| sCAL |
(专用公共数据块) |
否 |
是 |
在IDAT之前 |
IDAT |
图像数据块 |
是 |
否 |
与其他IDAT连续 |
| tIME |
图像最后修改时间数据块 |
否 |
是 |
无限制 |
| tEXt |
文本信息数据块 |
是 |
是 |
无限制 |
| zTXt |
压缩文本数据块 |
是 |
是 |
无限制 |
| fRAc |
(专用公共数据块) |
是 |
是 |
无限制 |
| gIFg |
(专用公共数据块) |
是 |
是 |
无限制 |
| gIFt |
(专用公共数据块) |
是 |
是 |
无限制 |
| gIFx |
(专用公共数据块) |
是 |
是 |
无限制 |
IEND |
图像结束数据 |
否 |
否 |
最后一个数据块 |
png 文件中,每个数据块由4个部分组成 length | type(name) | data | CRC, 说明如下
length: 4 bytes, data的长度,不包括type和CRC
type: 4 bytes, ASCII码([A-Z,a-z])
CRC: 4bytes
CRC(cyclic redundancy check)域中的值是对Chunk Type Code域和Chunk Data域中的数据进行计算得到的。CRC具体算法定义在ISO 3309和ITU-T V.42中,其值按下面的CRC码生成多项式进行计算: x32+x26+x23+x22+x16+x12+x11+x10+x8+x7+x5+x4+x2+x+1
除了高亮的关键数据块,还有下面比较有意思的数据块
tRNS
tRNS contains transparency information. For indexed images, it stores alpha channel values for one or more palette entries. For truecolor and grayscale images, it stores a single pixel value that is to be regarded as fully transparent.
tRNS包含透明度信息,
1.在索引图片中,它可以保存一或多个调色板像素对的alpha通道值。用来指明哪些像素需要透明,透明度是多少。然后剩下的像素透明度都被默认成255,完全不透明。
2.在灰度图片中,包含单个灰度级别值,格式如下:
Gray: 2 bytes, range 0 .. (2^bitdepth)-1
被指定的灰度值都会被当成是透明的,其他灰度值则完全不透明(如果bit depth小于16,则取最低有效位,其他位为0)
3.在真彩色图片中,包含单个RGB颜色值,格式如下:
Red: 2 bytes, range 0 .. (2^bitdepth)-1
Green: 2 bytes, range 0 .. (2^bitdepth)-1
Blue: 2 bytes, range 0 .. (2^bitdepth)-1
被指定的颜色值都会被当成是透明的,其他颜色值则完全不透明(如果bit depth小于16,则取最低有效位,其他位为0)
在带alpha通道的图片中,tRNS是被禁止使用的。
a.IHDR数据块
IHDR数据块存储了png图像的基本信息,一个图像中只能有一个IHDR数据块,并且也是png图像的第一个数据块。共有13个字节。记录的信息如下:
表1.2
| 域的名称 |
字节数 |
说明 |
| Width |
4 bytes |
图像宽度,以像素为单位 |
| Height |
4 bytes |
图像高度,以像素为单位 |
| Bit depth |
1 byte |
图像深度.索引彩色图像: 1,2,4或8 , 灰度图像: 1,2,4,8或16 真彩色图像: 8或16 |
| ColorType |
1 byte |
颜色类型. [0]:灰度图像, 1,2,4,8或16 [2]:真彩色图像,8或16 [3]:索引彩色图像,1,2,4或8 [4]:带α通道数据的灰度图像,8或16 [6]:带α通道数据的真彩色图像,8或16 |
| Compression method |
1 byte |
压缩方法(LZ77派生算法) |
| Filter method |
1 byte |
滤波器方法 |
| Interlace method |
1 byte |
隔行扫描方法. 0:非隔行扫描 1: Adam7(由Adam M. Costello开发的7遍隔行扫描方法) |
从这个表中可以得出,一张png图片最大的宽高(4294967300 × 4294967300)
这里的Bit depth一开始很难理解,引用维基百科两段话:
Pixels in PNG images are numbers that may be either indices of sample data in the palette or the sample data itself. The palette is a separate table contained in the PLTE chunk. Sample data for a single pixel consists of a tuple of between one and four numbers. Whether the pixel data represents palette indices or explicit sample values, the numbers are referred to as channels and every number in the image is encoded with an identical format.
The permitted formats encode each number as an unsigned integral value using a fixed number of bits, referred to in the PNG specification as the bit depth. Notice that this is not the same as color depth, which is commonly used to refer to the total number of bits in each pixel, not each channel. The permitted bit depths are summarized in the table along with the total number of bits used for each pixel.
The number of channels depends on whether the image is grayscale or color and whether it has an alpha channel. PNG allows the following combinations of channels, called the color type.
大意是:png图片的像素(Pixels)是调色板中样本数据的索引或者样本数据其本身,调色板是在PLTE数据块中的。单个像素的样本数据包含1~4个数字的元组。像素数据表示调色板索引或者明确的样本值,每个数字代表每个通道,每个数字都有唯一可识别的编码。
允许编码每个数字的格式是一个使用固定位数的unsigned整数值,在PNG中称为bit depth(位深)。位深和color depth(颜色深度)不同,颜色深度通常代表一个像素的总位数,不是每个通道的总位数。
通道数取决于这个图片是否是灰度图还是有alpha通道的色彩图
因此可以知道bit depth是一个通道的位数,bit depth在索引彩色图片和灰度图中使用,使得图片的一个像素点的大小可以小于一个字节
b.PLTE数据块(调色板数据块)
c.IDAT数据块
这部分的数据块存放的就是图像的一个个像素(使用压缩算法之后生成的像素),一张图像中可以存在多个IDAT数据块,这种编码方式虽然稍微增加了图像的大小,但是可以使得PNG图像以一种流的方式生成。例如在浏览器中打开一张非常大的PNG图像,如果网络很慢,我们可以看到图片是从上到下一点点打开的,这是因为即使整张图片没有加载完,仍然可以显示局部内容。
IDAT数据块是最重要的一部分,这里的数据会被隔行扫描方法(Interlace method)、滤波器(filtering)和压缩算法(compression)处理。这三个部分会在下面详细介绍。
并且要注意的是,IDAT数据块存储的数据并不是以字节为最小单位,在灰度图片和索引彩色图片中,一个字节可能会包含多个像素点,由bit depth指定。
d.IENT数据块
这段数据块标记PNG文件或者数据流已经结束,并且必须要放在文件的尾部。
正常情况下, png 文件的结尾为如下12个字符:
00 00 00 00 49 45 4E 44 AE 42 60 82
由于数据块结构的定义,IEND数据块的长度总是0(00 00 00 00,除非人为加入信息),数据标识总是IEND(49 45 4E 44),因此,CRC码也总是AE 42 60 82
4.隔行扫描方法
隔行扫描方法是为了图片被更先进的展示出来。在图片传输过程中,可以让图片的展示有淡入的效果。虽然平均下来稍微增加了存储的大小,但是给带来用户更快的显示效果。
- a.这个方法取值为0时,代表像素点是从左到右顺序存储,扫描线扫描时从上到下即可。
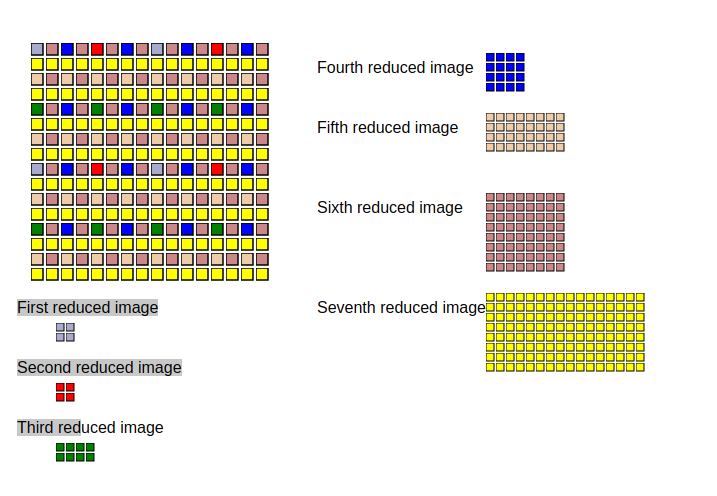
- b.这个方法取值为1时,被称为Adam7算法
Adam7分为7个扫描步骤,可见下图:
5.过滤器
过滤器中只有一种过滤方法,但是有多种过滤类型。过滤方法并不会影响数据的大小,也不会影响丢失任何信息,过滤的目的只有一个,为压缩方法提供更好压缩的数据,IDAT数据中的每一行第一个字节定义了过滤类型,过滤类型的介绍如下:
a.过滤类型0:None
也就是不做任何过滤
b. 过滤类型1:Sub
记录当前像素和左边像素的差值。左边起第一个像素是标准值,不做任何过滤
c. 过滤类型2:Up
记录X – B的值,即当前像素和上边像素点差值。如果当前行是第1行,则当前行数标准值,不做任何过滤。
d.过滤类型3:Average
记录当前像素与左边像素和上边像素的平均值的差值。
- 如果当前行数第一行:做特殊的Sub过滤,左边起第一个像素是标准值,不做任何过滤。其他像素记录该像素与左边像素的二分之一的值的差值。
- 如果当前行数不是第一行:左边起第一个像素记录该像素与上边像素的二分之一的值的差值,其他像素做正常的Average过滤。
e.过滤类型4:Paeth
记录X – Pr的值,这种过滤方式比较复杂,Pr的计算方式(伪代码)如下:
p = a + b - c
pa = abs(p - a)
pb = abs(p - b)
pc = abs(p - c)
if pa <= pb and pa <= pc then Pr = a
else if pb <= pc then Pr = b
else Pr = c
return Pr
如果当前行数第一行:做Sub过滤。
如果当前行数不是第一行:左边起第一个像素记录该像素与上边像素的差值,其他像素做正常的Peath过滤。
6.压缩算法
压缩算法当前只定义了一种,值为0,是使用一个滑动窗口的deflate/inflate压缩,这个算法可以调用zlib库来实现
7.关于压缩
对于一张图片,我们可以使用以上知识来完成一次无损压缩,以及去除所有的辅助数据块。但是很多场景下,常规的无损压缩并不能带来很高的压缩比,这个时候可以考虑使用有损压缩,大概的思路就是将总体颜色数减少到256以下(使用相近的颜色来代替),然后使用索引色彩来编码整张图片,带来很高的压缩比
实际操作验证
一级压缩图片(958.8k):https://www.myway5.com/wp-content/uploads/2017/11/output_1.png
九级压缩图片(857.0k):https://www.myway5.com/wp-content/uploads/2017/11/output_9.png
有损压缩图片(273.0k):https://www.myway5.com/wp-content/uploads/2017/11/test_tiny.png
原图(1.5m):https://www.myway5.com/wp-content/uploads/2017/11/test.png)
使用vim打开原图:
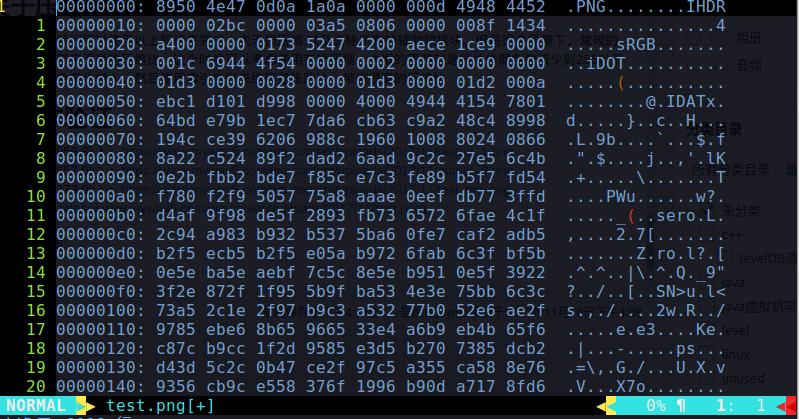
8950 4e47 0d0a 1a0a是png固定的头,
0000 000d是iHDR数据块的长度,为13,4948 4452是数据块的type,为IHDR,之后紧跟着是data, 0000 02bc是图片的宽度,0000 03a5是高度,08是Bit depth,也就是一个通道是8位,06是color type,这里表示图片是真彩色,00是压缩方法,png中目前只有一种,也就是LZ77派生的算法,00是滤波器方法,表示不使用,00是隔行扫描方法,代表不扫描。8f 1434 a4是四个字节的CRC校验码。
00 0000 01是sRGB数据块的长度(???),为1,73 5247 42是type,为sRGB,00是存储的一个字节数据,aece 1ce9是循环校验码
之后还有一个iDoT数据块,再紧接着才是IDAT数据块,下面就不分析了。
再打开9级压缩的图片
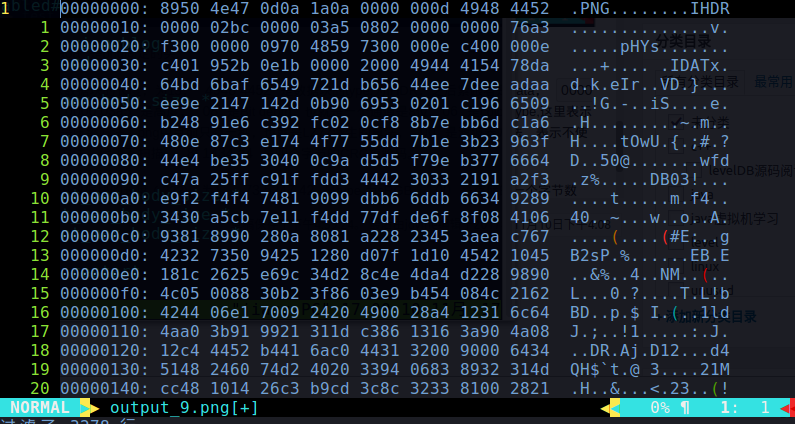
简单看一下,sRGB和iDOT数据块已经不存在了,IDAT数据块的长度发生了改变,其实就是被压缩了。这种压缩是无损的,9级压缩和1级压缩相差十几k的大小,但是压缩的越小,耗时也越长。
最后去看在tinypng上进行有损压缩的图片:
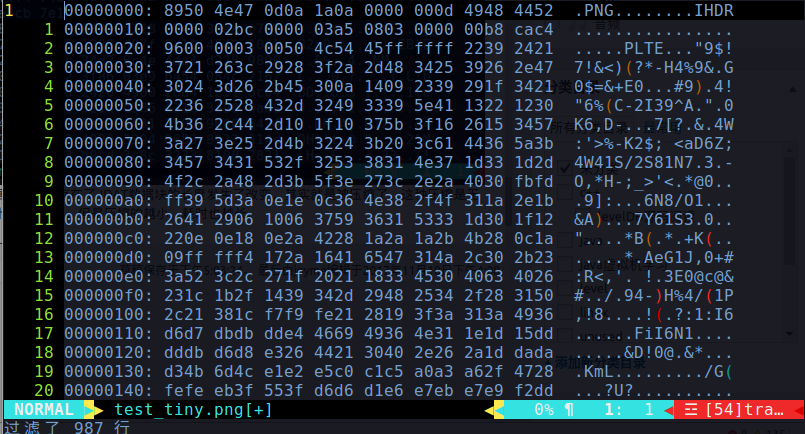
它多了一个PLTE字段,意味着这张图变成了索引彩色图片,索引彩色图片最关键的一点就是总颜色数不能超过256。如果这张图片的总颜色数没有256个,那么甚至可以说这次图片的压缩是无损的。但是一旦颜色数超过256,就需要将多个相近的颜色处理成一个颜色,也就是有损的压缩
参考
- [1] png文件结构分析:http://www.360doc.com/content/11/0428/12/1016783_112894280.shtml
- [2] php imagecreatefrom* 系列函数之 png:http://drops.xmd5.com/static/drops/tips-16034.html
- [3] Portable Network Graphics: https://en.wikipedia.org/wiki/Portable_Network_Graphics
- [4] png的故事:获取图片信息和像素内容: https://www.qcloud.com/community/article/864088
- [5] https://www.w3.org/TR/2003/REC-PNG-20031110/#figure48
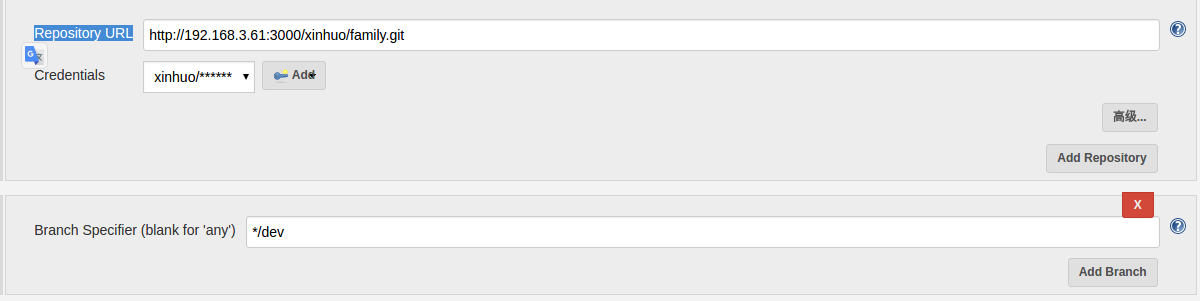 仓库地址可以是HTTP协议,也可以是SSH协议,然后记得在Credentials字段填入认证信息,HTTP协议可以是用户名和密码,SSH的话可以是秘钥。选择的是dev分支。之后在填写构建信息。
仓库地址可以是HTTP协议,也可以是SSH协议,然后记得在Credentials字段填入认证信息,HTTP协议可以是用户名和密码,SSH的话可以是秘钥。选择的是dev分支。之后在填写构建信息。 构建命令主要就是执行一个脚本
构建命令主要就是执行一个脚本