1. NAT
NAT 模式下,虚拟机连通外部网络类似于我们使用路由器上网。也就是说,虚拟机内部可以访问外部网络,外部网络无法直接连接虚拟机,但是可以通过端口转发的方式实现。
我们使用 virtualbox 启动一个 NAT 网络模式的虚拟机。查看它的网络接口:
$ ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 52:54:00:8a:fe:e6 brd ff:ff:ff:ff:ff:ff
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 08:00:27:8e:f8:c6 brd ff:ff:ff:ff:ff:ff
再看一下路由表:
$ ip route
default via 10.0.2.2 dev eth0 proto dhcp metric 100
10.0.2.0/24 dev eth0 proto kernel scope link src 10.0.2.15 metric 100
192.168.88.0/24 dev eth1 proto kernel scope link src 192.168.88.101 metric 101
默认的路由规则是通过 10.0.2.2 出去,这里 10.0.2.2 这个设备就相当于路由器的地址。并且虚拟机的 eth0 的地址 10.0.2.15 是通过 dhcp 来获得的。NAT 模式下的工作机制如下图:
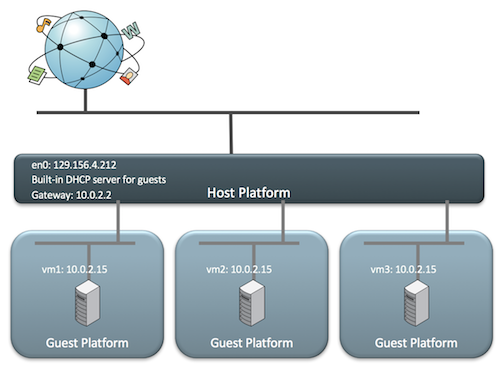
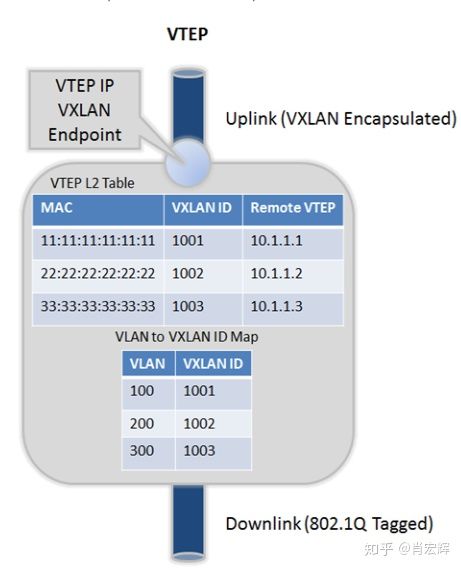
当虚拟机启动时,它会使用 DHCP 来获取一个 IP 地址。VirtualBox 会处理这个 DHCP 请求,并且告诉虚拟机它分配到的 IP 地址和网关地址。在这种模式下,每个虚拟机都会分配相同的 IP 地址(10.0.2.15),因为每个虚拟机都认为它们实在自己的隔离网络内。当它们通过网关(10.0.2.2)发送数据包时,VirtualBox重写这些包,让它们看起来是来自宿主机,而不是来自于虚拟机。
NAT 网络的特点如下:
- 虚拟机位于私有 LAN 中。
- VirtualBox 扮演一个 DHCP 服务。
- VirtualBox NAT 引擎来做地址转换。
- 目标服务看到的流量是来自于 VirtualBox 宿主机。
- 宿主机和虚拟机都不需要配置。
- 虚拟机作为客户端时是非常合适的。
- 虚拟机作为服务端不合适
Bridged Networking
桥接网络给我的第一印象就是和 linux 上的 bridge。在这种网络模式下,虚拟机和宿主机在网络拓扑中是平等的,宿主机上会有一个虚拟的 NIC 桥接到物理 NIC 上。关于这个 bridge 的实现,VirtualBox 在宿主机上使用了设备驱动来从物理网络适配器上过滤数据。因此这个驱动被称为 net filter。这使得 VirtualBox 可以从物理网络上拦截数据以及注入数据,就像是用软件实现了一个网络接口一样。
如下图所示:
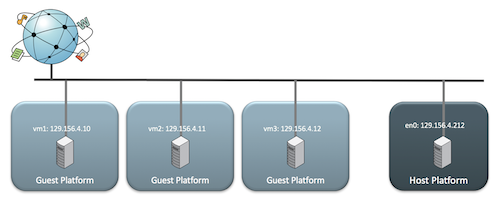
bridged networking 的特点如下:
- VirtualBox 负责桥接到主机网络(这也是在 linux 宿主机上并不能看到上面所谓的 bridge 的原因)
- 对于客户端或服务端的虚拟机都很友好
- 会消耗所处网络内的 IP 地址
- 可能需要对虚拟机进行配置
- 生产环境的最佳选择
Internal Networking
Internal Networking 和 bridged networking 类似,可以和外部的网络通信。但是这里的外部网络仅指可以在同一宿主机上的相同的内网的其他虚拟机。如下图所示:
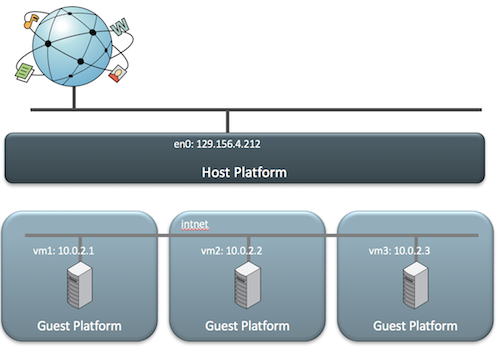
我们可以通过命令行创建一个 DHCP 服务,网络的名称是 intnet:
$ vboxmanage dhcpserver add -netname intnet --ip 10.10.0.1 --netmask 255.255.0.0 --lowerip 10.10.10.1 --upperip 10.10.10.255 --enable
然后在 VirtualBox 中创建虚拟机时加入这个网络即可。这个网络中的所有虚拟机都是和外界隔离的,包括宿主机。
Internal Networking 的特点是:
– 虚拟机可以看到其他在同一个网络内的虚拟机
– 宿主机看不到内部网络
– 网络需要手动配置
– 即使宿主机没有网络也可以工作
– 可以和 Bridged 网络一起使用
– 适合多层解决方案
Host-Only Networking
Host-Only Networking 和 Internal Networking 是相似的,你可以指定虚拟机位于的网络,比如说:vboxnet0。所有在 vboxnet0 上的虚拟机都可以看见彼此,此外宿主机也可以看见这些虚拟机。当然,其他外部的机器没有办法看到这个网络上的虚拟机,因此取名为 “Host-only”。
其网络拓扑图如下:
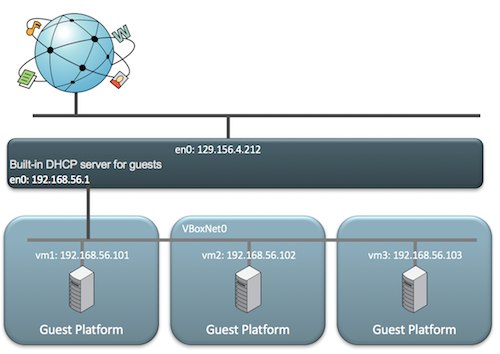
Host-Only 网络的特点如下:
– VirtualBox 为虚拟机和宿主机创建私有的内部网络
– 宿主机上可以看到新的软件 NIC
– VirtualBox 提供了 DHCP 服务
– 虚拟机 无法访问外部互联网
– 即使宿主机失去连接,虚拟机依然正常工作
– 适合开发的场景
参考资料
Chapter 6. Virtual Networking
Oracle VM VirtualBox: Networking options and how-to manage them