概述
PLEG 全称是 Pod Lifecycle Event Generator,用来为 kubelet 生成 container runtime 的 pod 生命周期事件,这样 kubelet 就可以根据 pod 的 spec 和 status 对比,来执行对应的控制逻辑。
在 1.1 及之前的 kubelet 中是没有 PLEG 的实现的。kubelet 会为每个 pod 单独启动一个 worker,这个 worker 负责向 container runtime 查询该 pod 对应的 sandbox 和 container 的状态,并进行状态同步逻辑的执行。这种 one worker per pod 的 polling 模型给 kubelet 带来了较大的性能损耗。即使这个 pod 没有任何的状态变化,也要不停的对 container runtime 进行主动查询。
因此在 1.2 中,kubelet 引入了 PLEG,将所有 container runtime 上 sandbox 和 container 的状态变化事件统一到 PLEG 这个单独的组件中,实现了 one worker all pods。这种实现相比于 one worker per pod 已经带来了较大的性能提升,详细实现会在后文进行介绍。但是默认情况下,仍然需要每秒一次的主动向 container runtime 查询,在 node 负载很高的情况下,依然会有一定的性能问题,比较常见的情况是导致 node not ready,错误原因是 PLEG is not healthy。
在 1.26 中,kubelet 引入了 Evented PLEG,为了和之前的 PLEG 实现区别,之前的 PLEG 称为 Generic PLEG。当然,Evented PLEG 并不是为了取代 Generic PLEG,而是和 Generic PLEG 配合,降低 Generic PLEG 的 polling 频率,从而提高性能的同时,也能保证实时性。
Generic PLEG
Generic PLEG 定时(默认1s)向 runtime 进行查询,这个过程称为 relist,这里会调用 cri 的 ListPodSandbox 和 ListContainers接口。runtime 返回所有的数据之后,PLEG 会根据 sandbox 和 container 上的数据,对应的 Pod 上,并更新到缓存中。同时,组装成事件向 PLEG Channel 发送。
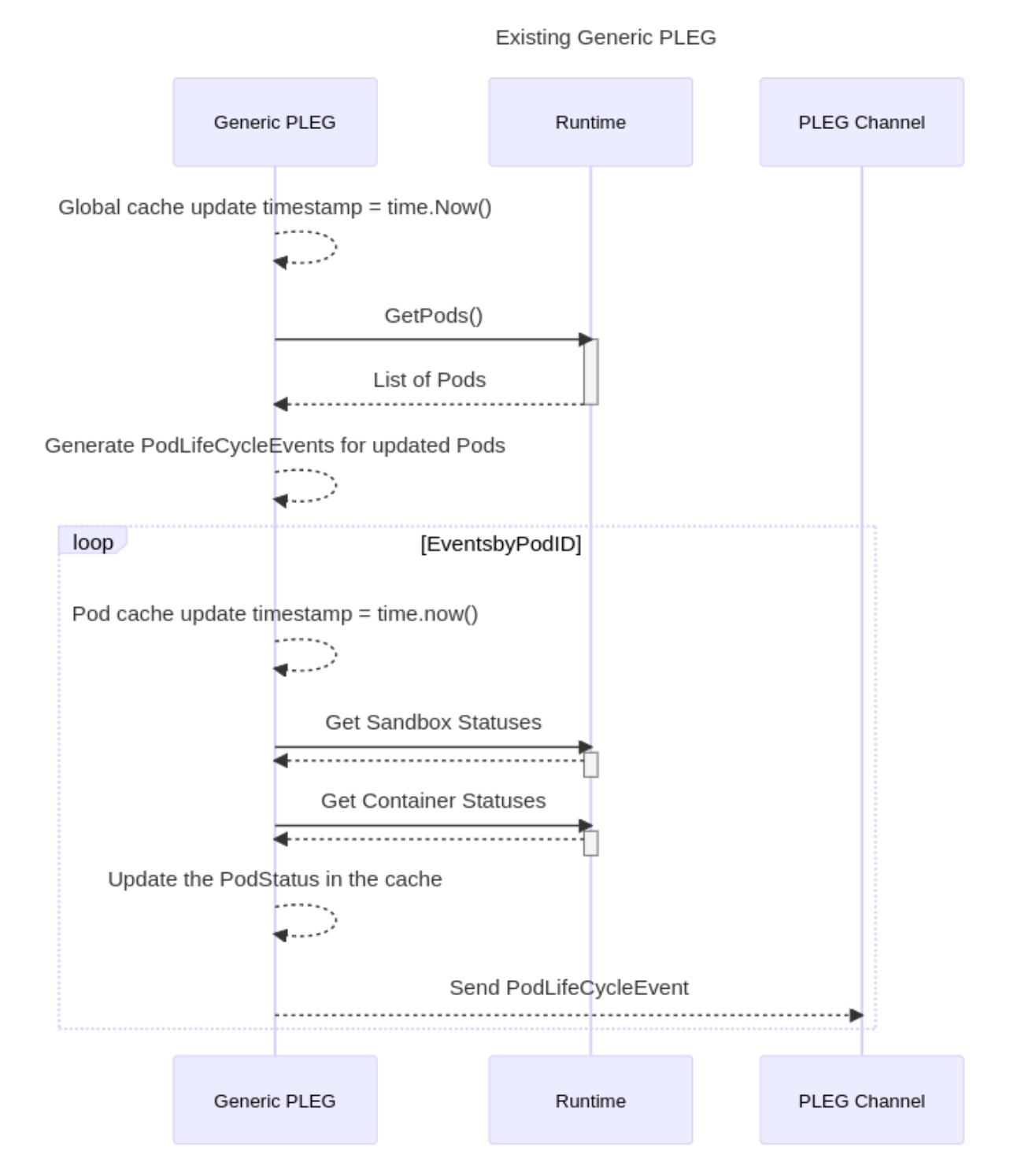
kubelet 会在 pod sync loop 中监听 PLEG Channel,从而针对状态变化执行相应的逻辑,来尽量保证 pod spec 和 status 的一致。
Evented PLEG
引入 Evented PLEG 后,对 Generic PLEG 做了些许调整,主要是 relist 的周期和阈值,以及对缓存的更新策略。
- relist 的同步周期由 1s 增加到 300s。同步阈值从 3min 增加到 10min。
- 缓存更新时,updateTime 不再是取本地的时间,而是 runtime 返回的时间。
除此之外,Generic PLEG 会和之前一样运行,这样也保证了及时 Evented PLEG 丢失了一些 状态变更的 event,也可以由 Generic PLEG 兜底。
Evented PLEG 会调用 runtime 的 GetContainerEvents 来监听 runtime 中的事件,然后生成 pod 的 event,并发送到 PLEG Channel 中供 kubelet pod sync loop 消费。
如果 Evented 不能按照预期工作(比如 runtime 不支持 GetContainerEvents),还会降级到 Generic PLEG。降级逻辑是:
- 停止自己。
- 停止已有的 Generic PLEG。
- 更新 Generic PLEG 的 relist 周期和阈值为 1s, 3min。
- 启动新的 Generic PLEG。
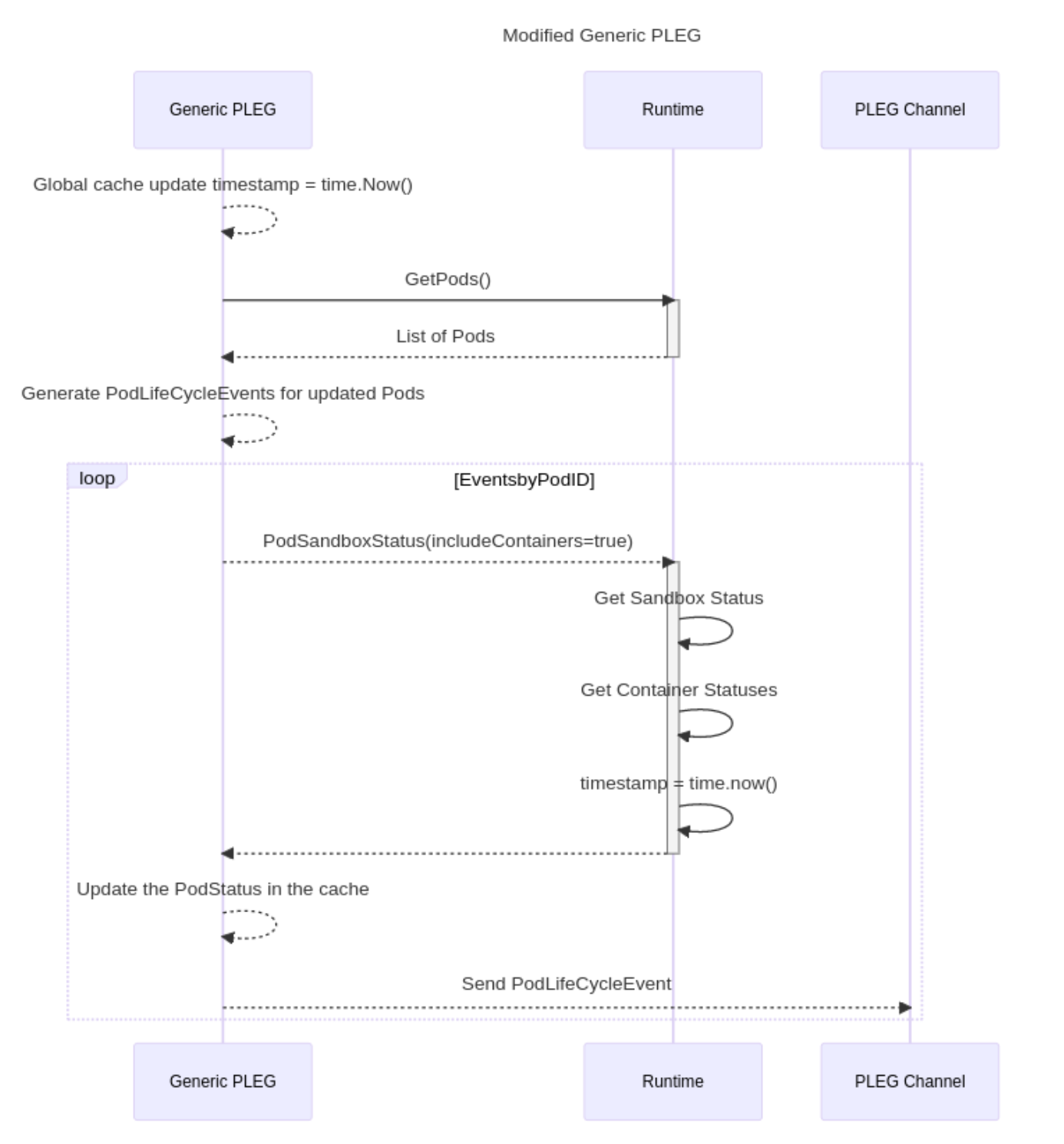
因为 Evented PLEG 和 Generic PLEG 会同时更新缓存,所以在更新时还会对比当前值和缓存值的时间戳,保证当前值是更新的状态,才会更新到缓存中。