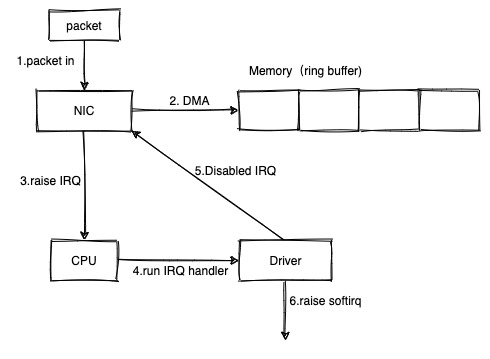
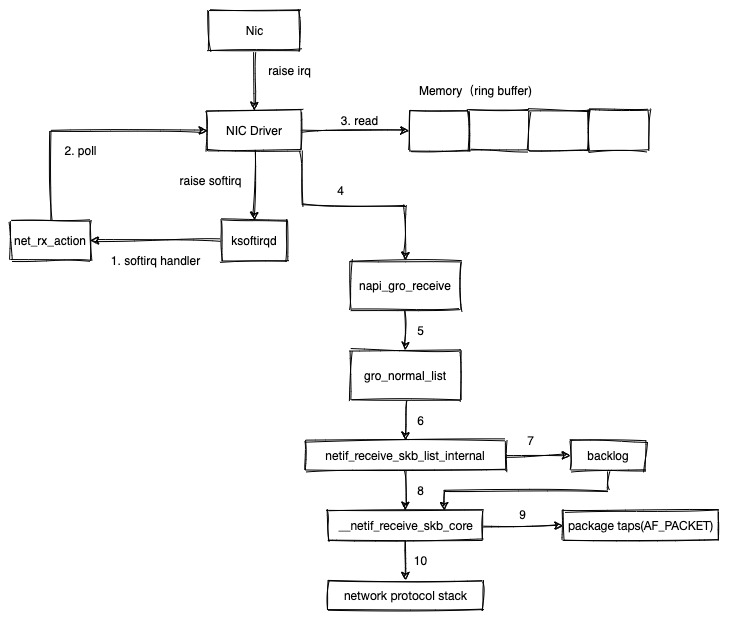
概述
当集群中所有的主机都在同一个二层时,calico cni 可以仅靠路由,使得所有的 Pod 网络互通。但是纯二层的环境在很多场景下都不一定能满足,因此当主机之间仅3层互通时,就可以使用 calico IPIP(全称 IP in IP) 模式。
IP in IP 是一种 IP 隧道协议,其核心技术点就是发送方将一个 IP 数据包封装到另一个 IP 数据包之中发送,接受方收到后,从外层 IP 数据包中解析出内部的 IP 数据包进行处理。常用在 VPN 等技术中,用来打通两个内网环境。
calico IPIP 流量分析
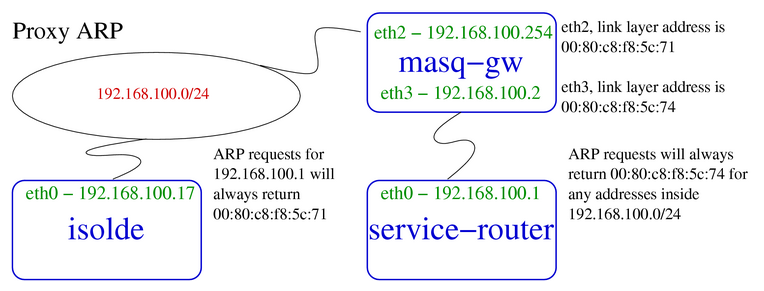
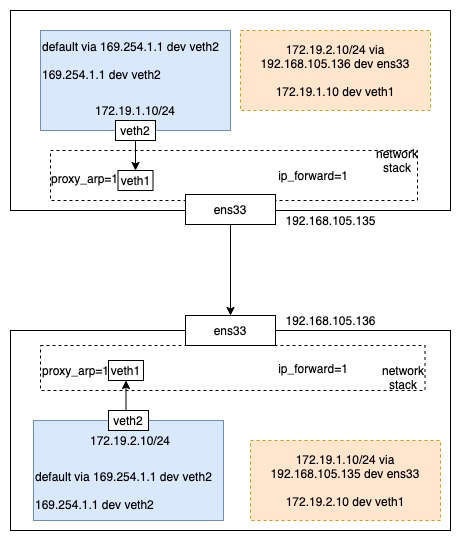
之前的文章proxy_arp在calico中的妙用简单讲了 calico 是如何通过路由打通不同主机上的 Pod 网络的,其实这个方案有一个前提,就是不同的主机之间需要二层互通。当网络环境满足不了时,就可以通过使用路由 + IPIP 的方式来打通网络。
这里可以通过一个简单的实验来验证一下该方案。
# node.sh
ip netns add n1
ip link add veth1 type veth peer name veth2
ip link set veth2 netns n1
ip netns exec n1 ip link set veth2 up
ip netns exec n1 ip route add 169.254.1.1 dev veth2 scope link
ip netns exec n1 ip route add default via 169.254.1.1
ip netns exec n1 ip addr add 172.19.1.10/24 dev veth2
ip link set veth1 up
ip route add 172.19.1.10 dev veth1 # 这个路由必须有
ip netns exec n1 ip route del 172.19.1.0/24 dev veth2 proto kernel scope link src 172.19.1.10
echo 1 > /proc/sys/net/ipv4/conf/veth1/proxy_arp
echo 1 > /proc/sys/net/ipv4/ip_forward
上面的脚本是用来创建一个虚拟的 Pod 的,可以在不同的主机上执行一下,这里要记得修改一下 IP 地址,来保证两个 Pod 的 IP 不同。
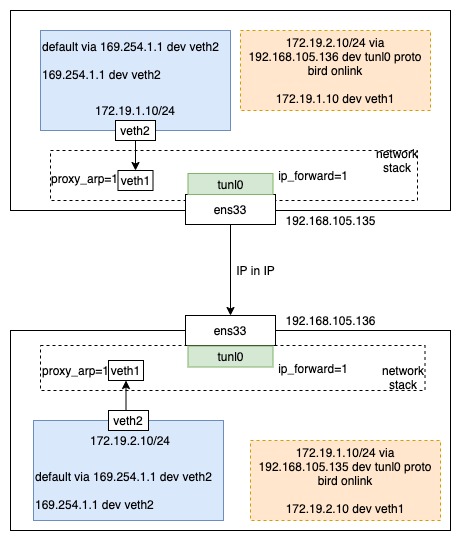
之后在宿主机上创建 IP 隧道。也是两台主机都要执行。
ip tunnel add mode ipip
ip link set tunl0 up
ip route add 172.19.1.0/24 via 192.168.105.135 dev tunl0 proto bird onlink
这里在创建 IP 隧道时,并没有指定隧道对端的地址,因为在实际的集群中,1对1的隧道是没使用场景的。而是使用路由告诉这个隧道的对端地址。这时候在 netns n1 内就可以 ping 通对端的 IP 了。
流程图如下