ARP 协议是什么
在具体学习 ARP(Address Resolution Protocol) 协议之前,我们应该先了解 ARP 协议的使用场景。大多数人对 ARP 协议可能和我一样,都有一个大概的印象。比如它是在已知 IP 地址的情况下,用来查找 MAC 地址的协议。这里也试着将 wikipedia 上的定义翻译过来,给出一个较为全面准确的定义:
ARP 协议是一种通信协议,用来发现网络层地址(比如 IPv4地址)关联的链路层地址(通常是 MAC 地址)。
以下的内容都来自于 wikipedia: https://en.wikipedia.org/wiki/Address_Resolution_Protocol
ARP 报文
ARP 协议使用一种格式来表示地址解析的请求或响应。ARP 消息的大小取决于链路层或者网络层地址的大小。报文头指明了每一层使用的网络类型以及地址的大小。报文头以 operation code(op) 结束,code 为 1 时表示请求,为 2 时表示响应。报文内容部分由四个地址组成,分别为发送者的硬件地址(Sender hardware address,简称 SHA)、发送者的网络层地址(Sender protocol address,简称 SPA)、目标的硬件地址(Target hardware address,简称 THA)、目标的网络层地址(Target protocol address,简称 TPA)。
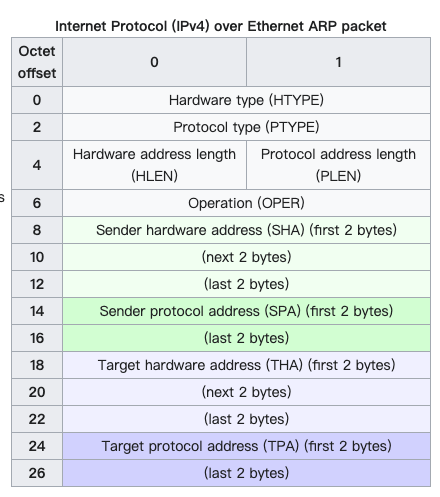
上图是以 IPv4 为例。这种情况下,SHA 和 THA 的大小为 48bit,SPA 和 TPA 的大小的 32bit。报文头的大小固定是 8 个字节。在 IPv4 的情况下就是总共有 28 个字节。下面,也以 IPv4 为例分别对 ARP 报文的每个字段进行解释。
1~2,Hardware type(HTYPE): 指明链路层协议类型,以太网是1。
3~4,Protocol type (PTYPE):指明网络层协议类型。对于 IPv4 来说,值是 0x0800。
5,Hardware address length(HLEN):硬件地址的长度。以太网地址的长度是6。
6,Protocol length(PLEN):网络层地址的长度。IPv4 地址长度是 4。
7~8,Operation(OP):指明发送方执行的操作,1是请求,2是响应。
到此,ARP 的报文头结束。
9~14,Sender hardware address(SHA):发送方的 MAC 地址。在 ARP 请求中,它代表的是发送请求方的地址。在 ARP 响应中,它代表的是这次 ARP 请求查找的主机地址。
15~18,Sender protocol address(SPA):发送方的网络层地址。
19~24,Target hardware address(THA):接收方的 MAC 地址。在 ARP 请求中,这个字段是被忽略的。在 ARP 响应中,这个字段用来表示 ARP 请求源主机的地址。
25~28,Target protocol address(TPA):接收方的网络层地址。
ARP 的以太网帧类型是 0x0806。
例子
在一个办公室中的两台电脑 c1(192.168.1.100) 和 c2(192.168.1.101) ,在局域网内通过以太网接口和交换机连接,中间没有网关和路由器。
下面我通过 linux 的网桥和 network namespace 来模拟这一场景:
# 准备交换机
ip link add name switch type bridge
# 准备一根网线,一头连接电脑c1,一头连接交换机
ip link add name veth_c10 type veth peer name veth_c11
# 准备一根网线,一头连接电脑c1,一头连接交换机
ip link add name veth_c20 type veth peer name veth_c21
# 准备电脑c1
ip netns add c1
# 准备电脑c2
ip netns add c2
# 将网线插入 c1
ip link set veth_c11 netns c1
# 将网线插入 c2
ip link set veth_c21 netns c2
# 将两根网线都插到交换机
ip link set veth_c10 master switch
ip link set veth_c20 master switch
# 启动交换机
ip link set switch up
# 启动c1
ip link set veth_c10 up
# 启动c2
ip link set veth_c20 up
# 为c1和c2分配ip
ip netns exec c1 ip addr add 192.168.1.100/24 dev veth_c11
ip netns exec c2 ip addr add 192.168.1.101/24 dev veth_c21
ip netns exec c1 ip link set veth_c11 up
ip netns exec c2 ip link set veth_c21 up
环境准备好了之后,c1 想要跟 c2 通信,此时 c1 需要知道 c2 的 MAC 地址。首先它会查找本地是否有缓存的 ARP 表。因为我们的环境刚刚创建好,所以肯定是没有缓存的,那么这个时候,c1 就会发送 ARP 请求,来查找 c2 的 MAC 地址。为了看到 c1 和 c2 之间的所有通信,我们可以用 tcpdump 或 wireshark 来抓交换机上的包,我这里为了展示的更清晰,采用 wireshark 来抓包。
从 c1 向 c2 发送一次 ping。
ip netns exec c1 ping -c 1 192.168.1.101
wireshark 抓包截图如下:

第一条是 ARP 请求。它是封装在以太网帧中的。
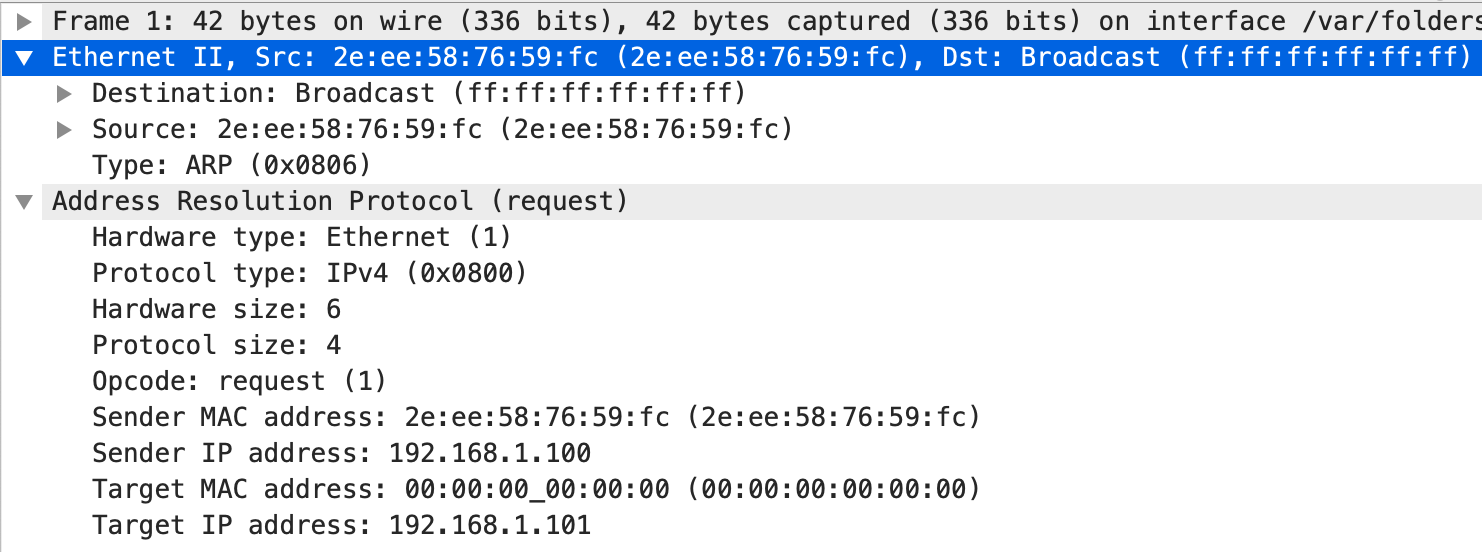
以太网帧的广播地址是 ff:ff:ff:ff:ff:ff,源地址是 2e:ee:58:76:59:fc。类型是 ARP。ARP 请求中因为不知道目标的 MAC 地址,所以是 00:00:00:00:00:00。十六进制表示如下:
 。
。
ARP 响应报文如下:
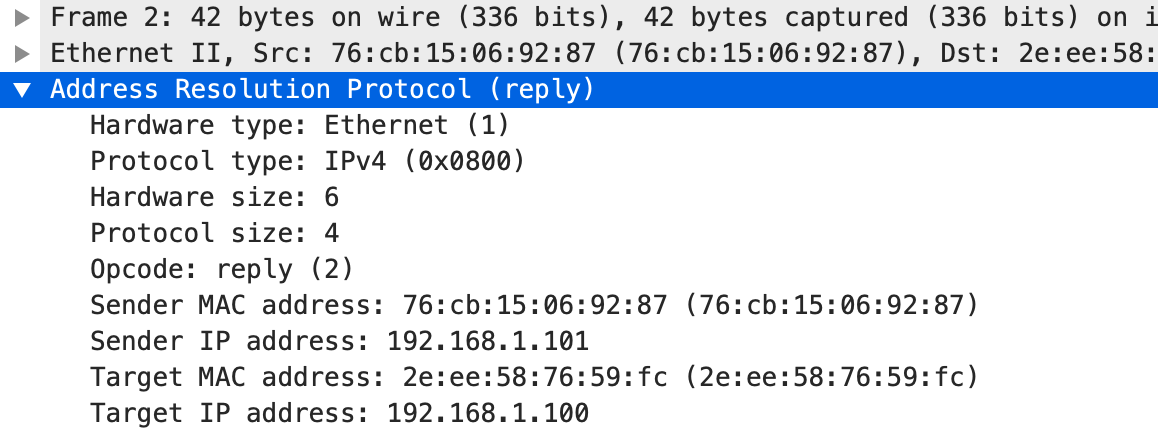 。通过这个响应我们也能知道 c1 的 MAC 地址是 2e:ee:58:76:59:fc,c2 的 MAC 地址是 76:cb:15:06:92:87。这个时候,我们也可以看一下 arp 表的情况。
。通过这个响应我们也能知道 c1 的 MAC 地址是 2e:ee:58:76:59:fc,c2 的 MAC 地址是 76:cb:15:06:92:87。这个时候,我们也可以看一下 arp 表的情况。
ip netns exec c1 arp -a
? (192.168.1.101) at 76:cb:15:06:92:87 [ether] on veth_c11
ARP 探针(ARP probe)
ARP 探针是一种 SPA 全为 0 的请求。在使用一个 IPv4 地址之前,实现了这个规范的主机必须检查这个地址是否已经在使用了。就是通过这样一个请求来检查的。
为什么要 SPA 全为 0 呢?这是为了防止如果存在冲突,这个请求可能会污染其他主机的 arp 表。
ARP 通告(ARP announcements)
ARP 可以用来作为一种简单的通告协议。当发送方的 IP 地址或者 MAC 地址发生改变后,用来更新其他主机的 MAC 表映射。ARP 通告请求在 target 字段上包含了 SPA 的值(TPA=SPA),THA 为 0,然后广播出去。因为 TPA 为自己的网络层地址,所以不会有其他主机的 ARP 响应。但是其他主机都会收到发送方的 MAC 地址和 IP 地址,那么就可以更新自己的缓存。
ARP 欺骗(ARP spoofing)和 代理 ARP(proxy ARP)
ARP 欺骗很好理解,就是让 ARP 请求的发送方收到错误的 ARP 响应。比如现在我们有三台电脑:
- c1: 192.168.1.100(2e:ee:58:76:59:fc)
- c2: 192.168.1.101(76:cb:15:06:92:87)
- c3: 192.168.1.102(12:07:6b:be:20:d2)
c1 想给 c2 发送数据,在 c1 发 ARP 请求的时候,我们将 ARP 响应中 c2 的 MAC 地址改为 c3 的 MAC地址。然后 c1 的数据就都会发给 c3 了,但是 c1 仍然认为自己在和 c2 通信,这就是 ARP 欺骗了。
代理 ARP 和 ARP 欺骗很像,只是目的不太一样。代理 ARP 的使用场景一般是两台主机不在同一个二层网内,这样通过代理 ARP 的方式来做流量转发。