概述
Gaia scheduler 是腾讯开源的在 Kubernetes 集群中做 GPU 虚拟化的方案,实现了为容器分配虚拟化 GPU 资源并加以限制,它的最大的优势就是不需要特殊的硬件支持,并且性能损耗很小。关于它的论文,地址在这里:Gaia Scheduler: A Kubernetes-Based Scheduler Framework。如果想要理解这个项目,强烈建议先读这篇论文。
Gaia Scheduler 可以分为 4 个组件:
- GPU Manager: 作为 device plugin 向 kubelet 注册。共注册了两个设备,包括 vcore 和 vmemory,支持两种计算资源:
tencent.com/vcuda-core和tencent.com/vcuda-memory,分别用来做 GPU 计算资源和 GPU 内存资源的请求和限制。 -
GPU Scheduler: 这里的 scheduler 并不是 kubernetes 的调度器,是 GPU Manager 在收到 kubelet 的 Allocate 调用后,它需求将设备挂载给容器。为了实现最佳的 GPU 挂载,就有这样一个专门的 Scheduler 来根据节点上当前的 GPU 拓扑和资源占用情况进行调度。
-
vGPU Manager: vGPU Manager 是具体负责管理容器的组件,包括监控容器状态,传递配置,和容器内的vGPU Library通信,以及在容器死亡后进行回收操作。
-
vGPU Library: vGPU Library 虽然相关的代码量不多,但它是 Gaia Scheduler 最重要的部分。因为它是实现 GPU 虚拟化的核心。通过覆盖容器中的 LD_LIBRARY_PATH 以及自定义了
libcuda-control.so实现对 CUDA API 的拦截。
Gaia Scheduler 主要由三个项目组成: gpu-manager 和 vcuda-controller,gpu-admission。但是这里的 gpu-manager 是 Gaia Scheduler 的主要实现,包含了上述的 4 个组件,vcuda-controller 就是 vGPU Library,已经被打包到了 gpu-manager 这个项目中。gpu-manager 需要配合 gpu-admission 项目来完成 GPU Scheduler 的工作。不要因此产生误解。下文中我们主要就 gpu-manager 这个项目进行分析。
启动流程分析
gpu-manager 本身主要作为 kubernetes 的 device plugin 来实现的,定义了两种设备: vcuda-core 和 vcuda-memory,我们的应用通过 pod 的资源字段进行申请,然后 kube-scheduler 会根据节点上的资源状态进行调度。因此,你最好还需要了解 kubernetes 的 device plugin 的开发知识。关于 device plugin 的开发,可以看之前的一篇文章:Kubernetes开发知识–device-plugin的实现。
启动参数
分析一个项目从启动参数开始,可以帮助我们快速了解:
- driver: 这个是 GPU 的驱动,当前的默认值是 nvidia,很显然该项目可以扩展支持其他类型的 GPU。
- extra-config: 额外的配置,这个参数暂时看不出来有什么特别
- volume-config: 这里的 volume 指的是一些动态链接库和可执行文件的位置。也就是 gpu-manager 需要拦截调用的一些库
- docker-endpoint: 用来挂载到容器中和 docker 做通信的,默认位置是
unix:////var/run/docker.sock - query-port: 统计信息服务的查询接口
- query-port: 统计信息服务的监听地址
- kubeconfig: 用来授权的配置文件
- standalone: 暂时还不清楚的参数
- sample-period: gpu-manager 会查询 gpu 设备的使用情况,这个参数用来设定采样周期
- node-labels: 给节点自动打标签
- hostname-override: gpu-manager 在运行时,只关注自己节点上的 pod,这主要是通过 hostname 来辨认的
- virtual-manager-path: gpu-manager 会为所有需要虚拟 gpu 资源的 pod 创建唯一的文件夹,文件夹的路径就在这个地址下。
- device-plugin-path: kubernetes 默认的 device plugin 的目录地址
- checkpoint-path: gpu-manager 会产生 checkpoint 来当缓存用
- share-mode: gpu-manager 最大的特点就是将一个物理 gpu 分成多个虚拟 gpu,也就是共享模式
- allocation-check-period: 检查分配了虚拟 gpu 资源的 pod 的状态,及时回收资源
- incluster-mode: 是否在集群内运行
服务启动
gpu-manager 推荐的部署方案是通过 kubernetes 的 daemonset,然后配置 node selector 调度到指定的节点上。然后 gpu-manager 就开始在指定节点上启动了。
srv := server.NewManager(cfg)
go srv.Run()
这里,我们需要看一下这个 srv 的具体实现,首先是它的结构体:
type managerImpl struct {
config *config.Config
allocator allocFactory.GPUTopoService // gpu 容器调度分配
displayer *display.Display // gpu 使用情况可视化服务
virtualManager *vitrual_manager.VirtualManager // 负责管理 vgpu
bundleServer map[string]ResourceServer
srv *grpc.Server
}
config 包含了我们上面的所有参数,就不进去细看了。
allocator 负责在容器调度到节点上后,为其分配具体的设备资源。allocator 实现了探测节点上的 gpu 拓扑架构,然后以最佳性能,最少碎片为目的使用最优的方案进行资源分配。
displayer 是将 gpu 的使用情况输出,方便我们查看。
virtualManager 负责 vgpu 分配后的管理工作。
bundleServer 包含 vcore,vmemory,我们上面提到这两种资源以 device plugin 的方式进行注册,因此他们需要启动 grpc server。
srv: 将 gpu display server 注册到这个 grpc server 中。
接下来,我们就可以分析 srv.Run() 方法具体执行了哪些内容。为了先对整个流程有个大概的印象,我将内容整理成以下条目:
- 启动 volumeManager,将节点上和 nvidia gpu (包括cuda) 的所有可执行文件和库移动到 /etc/gpu-manager/vdriver 中。并且将关键的库替换成 vcuda-control,实现 cuda 调用的拦截。
- watchdog 创建 pod 缓存并监控 pod,之后所有关于 pod 的操作都来源于这里。
- watchdog 给节点打上标签
- 启动 virtualManager
- gpu 拓扑结构感知。
- 初始化资源分配器
- 设置 vcuda, vmemory, display 的 grpc 服务
- 启动 metrics 的 http 服务,主要是提供给 prometheus
- 启动 vcuda,vmemory 的 grpc 服务
- 启动 display 的 grpc 服务
接下来,我们具体来分析每一步是如何做的。当然,这里只会挑一些重点的部分。
volumeManager 的启动
func (vm *VolumeManager) Run() (err error) {
// ldcache 是动态链接库的缓存信息
cache, err := ldcache.Open()
defer func() {
if e := cache.Close(); err == nil {
err = e
}
}()
vols := make(VolumeMap)
for _, cfg := range vm.Config {
vol := &Volume{
Path: path.Join(cfg.BasePath, cfg.Name),
}
if cfg.Name == "nvidia" {
// nvidia 库的位置
types.DriverLibraryPath = filepath.Join(cfg.BasePath, cfg.Name)
} else {
// origin 库的位置
types.DriverOriginLibraryPath = filepath.Join(cfg.BasePath, cfg.Name)
}
for t, c := range cfg.Components {
switch t {
case "binaries":
// 调用 which 来查找可执行文件的位置
bins, err := which(c...)
// 将实际位置存起来
vol.dirs = append(vol.dirs, volumeDir{binDir, bins})
case "libraries":
// 是库的话,就从 ldcache 里面去找
libs32, libs64 := cache.Lookup(c...)
// 将 library 位置存起来
vol.dirs = append(vol.dirs, volumeDir{lib32Dir, libs32}, volumeDir{lib64Dir, libs64})
}
vols[cfg.Name] = vol
}
}
// 找到了需要的库位置之后,做 mirror 处理
if err := vm.mirror(vols); err != nil {
return err
}
return nil
}
这段代码的前半部分都是在查找指定的动态链接库和可执行文件,这些文件是在 volume.conf 这个配置文件中指定的,通过参数传进来。查找动态链接库时,使用的是 ldcache,查找可执行文件时,使用了系统的 which 指令。找到之后会将其所在位置记录下来。接着就是对找到的库做 mirror 处理。
func (vm *VolumeManager) mirror(vols VolumeMap) error {
// nvidia 和 origin
for driver, vol := range vols {
if exist, _ := vol.exist(); !exist {
// 这里的path是/etc/gpu-manager/vdriver下面
if err := os.MkdirAll(vol.Path, 0755); err != nil {
return err
}
}
for _, d := range vol.dirs {
vpath := path.Join(vol.Path, d.name)
// 创建 bin lib lib64
if err := os.MkdirAll(vpath, 0755); err != nil {
return err
}
// For each file matching the volume components (blacklist excluded), create a hardlink/copy
// of it inside the volume directory. We also need to create soname symlinks similar to what
// ldconfig does since our volume will only show up at runtime.
for _, f := range d.files {
glog.V(2).Infof("Mirror %s to %s", f, vpath)
if err := vm.mirrorFiles(driver, vpath, f); err != nil {
return err
}
if strings.HasPrefix(path.Base(f), "libcuda.so") {
driverStr := strings.SplitN(strings.TrimPrefix(path.Base(f), "libcuda.so."), ".", 2)
types.DriverVersionMajor, _ = strconv.Atoi(driverStr[0]) // 驱动版本号
types.DriverVersionMinor, _ = strconv.Atoi(driverStr[1])
glog.V(2).Infof("Driver version: %d.%d", types.DriverVersionMajor, types.DriverVersionMinor)
}
if strings.HasPrefix(path.Base(f), "libcuda-control.so") {
vm.cudaControlFile = f
}
}
}
}
vCudaFileFn := func(soFile string) error {
if err := os.Remove(soFile); err != nil {
if !os.IsNotExist(err) {
return err
}
}
if err := clone(vm.cudaControlFile, soFile); err != nil {
return err
}
glog.V(2).Infof("Vcuda %s to %s", vm.cudaControlFile, soFile)
l := strings.TrimRight(soFile, ".0123456789")
if err := os.Remove(l); err != nil {
if !os.IsNotExist(err) {
return err
}
}
if err := clone(vm.cudaControlFile, l); err != nil {
return err
}
glog.V(2).Infof("Vcuda %s to %s", vm.cudaControlFile, l)
return nil
}
if vm.share && len(vm.cudaControlFile) > 0 {
if len(vm.cudaSoname) > 0 {
for _, f := range vm.cudaSoname {
if err := vCudaFileFn(f); err != nil {
return err
}
}
}
if len(vm.mlSoName) > 0 {
for _, f := range vm.mlSoName {
if err := vCudaFileFn(f); err != nil {
return err
}
}
}
}
return nil
}
这段代码先会对所有上面查找到的库或可执行文件调用 mirrorFiles,但是记录下来了 libcuda.so 的版本号和 libcuda-control.so 的位置。注意,这个 libcuda-control 就是 vcuda-control 项目生成的用来拦截 cuda 调用的库。
然后将 cudaControlFile clone到所有 cudaSoname 和 mlSoName 中库的位置。这个 clone 方法会先尝试硬链接过去,如果失败就直接复制过去。这里的 cudaControlFile 就是我们上面所说的 libcuda-control.so 啦。cudaSoname 和 mlSoName 包含了所有需要被拦截调用的库。这样子就实现了拦截所有的 cuda 调用。下面我们在看一下 mirrorFiles 这个方法就可以了。
// driver 是配置文件中的 "nvidia" 或 "origin"
// vpath 是要 mirror 到的位置,在 /etc/gpu-manager/vdriver 下面
func (vm *VolumeManager) mirrorFiles(driver, vpath string, file string) error {
// In computing, the Executable and Linkable Format (ELF, formerly named Extensible Linking Format), is a common standard file format for executable files, object code, shared libraries, and core dumps
obj, err := elf.Open(file)
defer obj.Close()
// 黑名单机制,具体用处还不清楚,跟 nvidia 的驱动相关
ok, err := blacklisted(file, obj)
if ok {
return nil
}
l := path.Join(vpath, path.Base(file))
// 不管有没有,先尝试把 gpu-manager 里面的移除
if err := removeFile(l); err != nil {
return err
}
// clone 优先硬连接,其次是复制文件到指定位置
if err := clone(file, l); err != nil {
return err
}
// 从 elf 中获取当前库的 soname
soname, err := obj.DynString(elf.DT_SONAME)
if len(soname) > 0 {
// 将获取到 soname 组成路径
l = path.Join(vpath, soname[0])
// 如果文件和它的soname不一致(是否可以认为这个文件是软链接过去的)
if err := linkIfNotSameName(path.Base(file), l); err != nil && !os.IsExist(err) {
return err
}
// XXX Many applications (wrongly) assume that libcuda.so exists (e.g. with dlopen)
// Hardcode the libcuda symlink for the time being.
if strings.Contains(driver, "nvidia") {
// 这里为什么要移除 libcuda.so 和 libnvidia-ml.so 的软链接
// 因为gpu调用会涉及到这两个库,这两个库会软链接到真实的库上。移除后替换成拦截的库
// Remove libcuda symbol link
if vm.share && driver == "nvidia" && strings.HasPrefix(soname[0], "libcuda.so") {
os.Remove(l)
vm.cudaSoname[l] = l
}
// Remove libnvidia-ml symbol link
if vm.share && driver == "nvidia" && strings.HasPrefix(soname[0], "libnvidia-ml.so") {
os.Remove(l)
vm.mlSoName[l] = l
}
// XXX GLVND requires this symlink for indirect GLX support
// It won't be needed once we have an indirect GLX vendor neutral library.
if strings.HasPrefix(soname[0], "libGLX_nvidia") {
l = strings.Replace(l, "GLX_nvidia", "GLX_indirect", 1)
if err := linkIfNotSameName(path.Base(file), l); err != nil && !os.IsExist(err) {
return err
}
}
}
}
return nil
}
这段代码中,先使用 blacklisted 排除一些不需要处理的库,然后尝试将库或可执行文件 clone 到我们的 /etc/gpu-manager/vdriver 下面。/etc/gpu-manager/vdriver 下面有两个文件夹,一个是 nvidia,保存了已经被我们拦截的库,一个是 origin,这里面是原始的未处理的库。同时,还将 libcuda.so 和 libnvidia-ml.so 移除了,这样就调用不到真实的库了,转而在之后用我们拦截的库来替换这几个文件。
至此,volumeManager 分析结束。
gpu 拓扑结构感知
关于 gpu 拓扑结构这一块,主要是为了在之后做资源分配时选择最优方案用的。腾讯也有分享过这一块的资料(腾讯基于 Kubernetes 的企业级容器云实践):
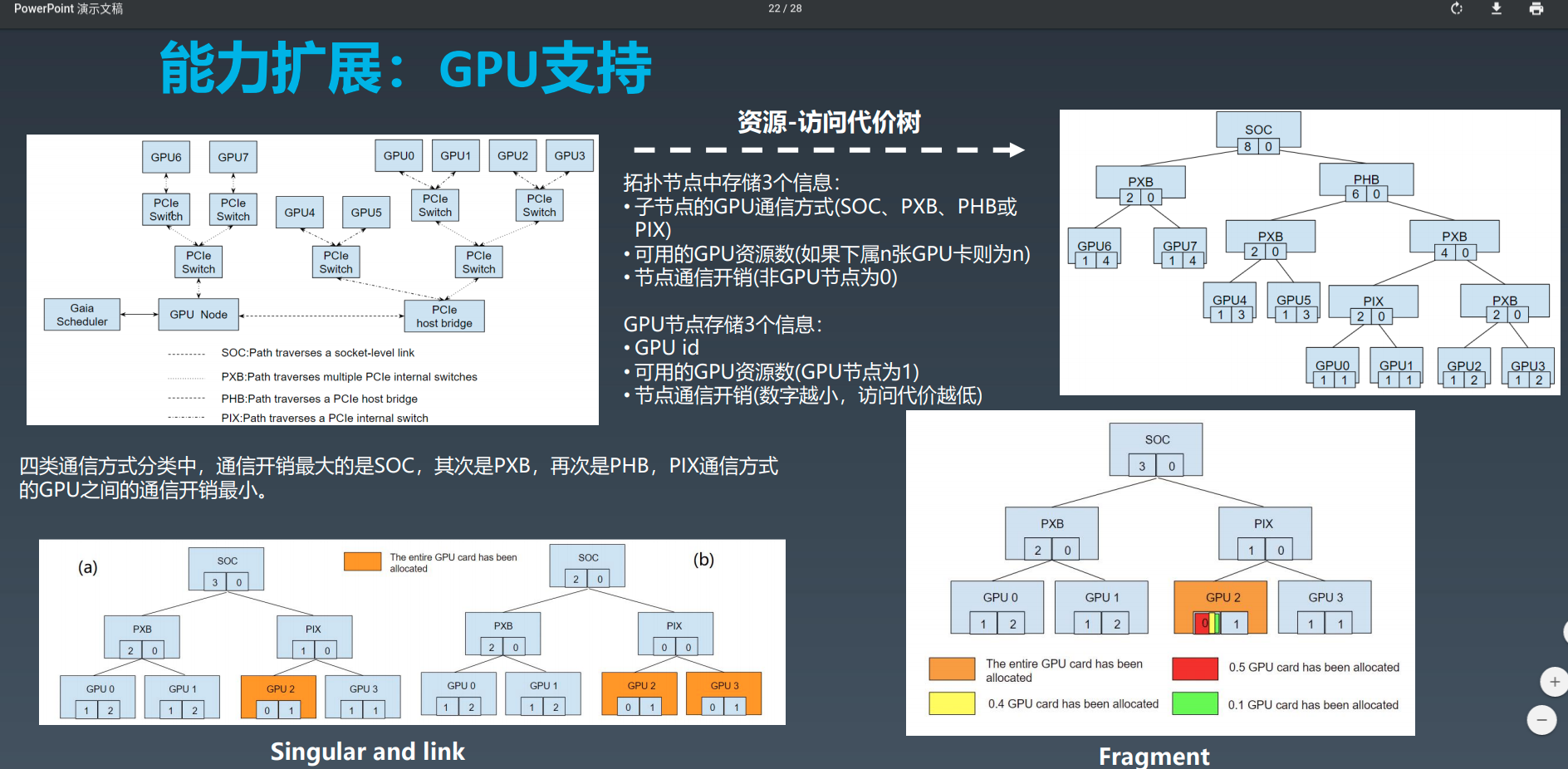
这里不影响我们理解整个工作机制,所以先不分析。
初始化资源分配器
// 分配器,根据driver调用相应的分配器
initAllocator := allocFactory.NewFuncForName(m.config.Driver)
if initAllocator == nil {
return fmt.Errorf("can not find allocator for %s", m.config.Driver)
}
m.allocator = initAllocator(m.config, tree, client)
这里的 initAllocator 对应的方法是:
//NewNvidiaTopoAllocator returns a new NvidiaTopoAllocator
func NewNvidiaTopoAllocator(config *config.Config, tree device.GPUTree, k8sClient kubernetes.Interface) allocator.GPUTopoService {
runtimeRequestTimeout := metav1.Duration{Duration: 2 * time.Minute}
imagePullProgressDeadline := metav1.Duration{Duration: 1 * time.Minute}
dockerClientConfig := &dockershim.ClientConfig{
DockerEndpoint: config.DockerEndpoint,
RuntimeRequestTimeout: runtimeRequestTimeout.Duration,
ImagePullProgressDeadline: imagePullProgressDeadline.Duration,
}
_tree, _ := tree.(*nvtree.NvidiaTree)
cm, err := checkpoint.NewManager(config.CheckpointPath, checkpointFileName)
if err != nil {
glog.Fatalf("Failed to create checkpoint manager due to %s", err.Error())
}
alloc := &NvidiaTopoAllocator{
tree: _tree,
config: config,
evaluators: make(map[string]Evaluator),
dockerClient: dockershim.NewDockerClientFromConfig(dockerClientConfig),
allocatedPod: cache.NewAllocateCache(),
k8sClient: k8sClient,
queue: workqueue.NewRateLimitingQueue(workqueue.DefaultControllerRateLimiter()),
stopChan: make(chan struct{}),
checkpointManager: cm,
}
// Load kernel module if it's not loaded
alloc.loadModule()
// Initialize evaluator
alloc.initEvaluator(_tree)
// Read extra config if it's given
alloc.loadExtraConfig(config.ExtraConfigPath)
// Process allocation results in another goroutine
go wait.Until(alloc.runProcessResult, time.Second, alloc.stopChan)
// Recover
alloc.recoverInUsed()
// Check allocation in another goroutine periodically
go alloc.checkAllocationPeriodically(alloc.stopChan)
return alloc
}
allocator 调用 loadModule() 来启用 nvidia 的内核模块。
调用 initEvaluator(_tree) 来初始化评估器,这里的 _tree 就是感知到的 gpu 拓扑结构。
调用 loadExtraConfig(config.ExtraConfigPath) 来加载启动时传入的额外参数配置文件。
go wait.Until(alloc.runProcessResult, time.Second, alloc.stopChan) 创建了新的协程来处理分配结果。
recoverInUsed() 是恢复 gpu 分配结果。比如在 gpu-manager 重启之后,之前的 gpu 分配结果都丢失了,但是节点上还有大量的容器正在占用 gpu,这个方法会通过查找节点上存活的容器,通过 docker endpoint, 调用 InspectContainer 获取容器中占用的 device id,然后标记该设备和容器之间的占用关系。
go alloc.checkAllocationPeriodically(alloc.stopChan) 创建新的协程来周期性的检查资源分配情况。如果是 Failed 和 Pending 状态的容器,就根据错误信息检查是否应该删除它们,然后如果这些 pod 的控制器是 deployment 类似的,就尝试删除它们,这样控制器会重新创建这些 pod 进行调度,让这些 pod 恢复到正常运行状态。
启动各种服务
vcuda,vmemory 的 grpc 服务是 device plugin 的机制。metrics service 是提供给 prometheus 调用的,以监控该节点的相关信息。display 服务会打印 gpu 拓扑结构的相关信息。
Device plugin 的注册

这张图是 device plugin 注册的时序图。gpu-manager 的注册方法是:
func (m *managerImpl) RegisterToKubelet() error {
socketFile := filepath.Join(m.config.DevicePluginPath, types.KubeletSocket)
dialOptions := []grpc.DialOption{grpc.WithInsecure(), grpc.WithDialer(utils.UnixDial), grpc.WithBlock(), grpc.WithTimeout(time.Second * 5)}
conn, err := grpc.Dial(socketFile, dialOptions...)
if err != nil {
return err
}
defer conn.Close()
client := pluginapi.NewRegistrationClient(conn)
for _, srv := range m.bundleServer {
req := &pluginapi.RegisterRequest{
Version: pluginapi.Version,
Endpoint: path.Base(srv.SocketName()),
ResourceName: srv.ResourceName(),
Options: &pluginapi.DevicePluginOptions{PreStartRequired: true},
}
glog.V(2).Infof("Register to kubelet with endpoint %s", req.Endpoint)
_, err = client.Register(context.Background(), req)
if err != nil {
return err
}
}
return nil
}
这里分别注册了 vcuda 和 vmemory。vcuda 和 vmemory 的 Allocate 方法都指向了同一个方法,写在了 service/allocator/nvidia/allocator.go 中。
至此,gpu-manager 的启动流程结束。接下来的 gpu-manager 的职责就是等待 kubelet 通过 grpc 的调用,在容器调度到节点的时候进行资源设备的分配,必要目录的挂载等工作了。具体的可以见下一篇文章
最后,提供一个简单的脑图帮助理解:
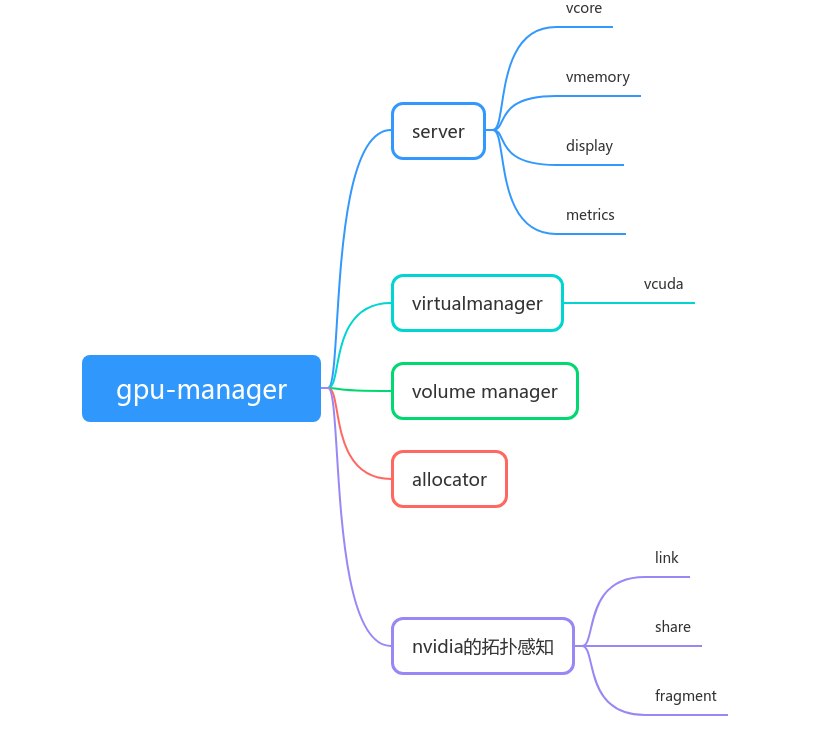
换主题了,这个挺好看的
好像是wordpress自带的?
在TKE这个方案中我们如果要替换GPU为其他厂商的话需要怎么修改呢?对于volumeManager还是有些迷糊,这里需要hook的库有这么多吗?