一、概述
goroutine 是 go 语言的特色之一,在 go 语言中,你可以轻易的使用 go 关键字来创建一个协程运行一段代码,协程在使用上和我们常说的线程相似,但是在 go 中,协程的实现并非是直接使用线程。原因有二:
- 线程的实现由操作系统决定,它附带了太多额外的特性,比如线程有它自己的信号掩码,线程能够被赋予 CPU affinity 功能,线程能够被添加到 Cgroup 中,线程所使用的资源也可以被查询到,线程的栈空间大小默认是 2M 等等。这些在 goroutine 中不需要的特性带来了额外的性能开销。
-
除了上面的性能问题,在 go 语言的编程模型中,操作系统无法作出最佳的决策。比如在运行一次垃圾收集时,go 的垃圾收集器要求所有线程都被停止,并且内存处于一致性状态(关于内存一致性,可以参考这篇文章:内存一致性模型)。这个涉及到要等待全部运行时线程(running threads)到达一个点(point),我们事先知道在这个点内存是一致的。当在一个随机点上调度了多个线程,你不得不等待他们中的大多数到达一致性状态。go 调度程序可以决定仅在知道内存一致的点上进行调度,这样在任何时刻,当前没有被调度的线程是处于内存一致状态的,这意味着当我们要为垃圾收集停止线程运行时,我们只需要等待那些 CPU 核心上运行的线程。
因此,go 语言实现一个自己的调度器,它可以创建更轻量的线程,也就是 goroutine,同时,调度算法需要更智能,以提升大量并发下的性能。
在讨论 go 的调度器之前,我们还要讨论一下常见的线程模型,具体的内容可以参考这篇文章:内核线程与用户线程的一点小总结.
我们根据线程的调度实现,将线程分为内核线程和用户线程。其中,内核线程是由操作系统调度,而用户线程是由用户自己实现的调度器进行调度。根据用户线程和内核线程的关系分为下面几种线程模型:
1:1模型
1:1 模型很简单,就是将一个用户线程映射或绑定到一个内核线程上,但是这会导致线程的上下文切换会很慢。
N:1模型
N:1 模型中会将多个用户线程映射或绑定到一个内核线程上,这样多个用户线程之间的上下文切换会很快,但是缺点是没法利用多核的优势。
M:N模型
1:1 模型 和 N:1 模型都有它们各自的缺点,因此 go 调度器中使用了 M:N 模型,既能保证利用到多核的优势,也能保证更快的上下文切换。这也是我们接下来要讨论的问题。
二、go 1.0 的调度器实现方案
go 1.0 的调度器实现方案其实并不是这篇文章的关注点,因为它的生命周期太短。之所以要拿出来单独说,是为了更好的理解 go 1.1 中调度器实现方案解决的问题以及带来的性能提升。
为了更好的阐述这中间的机制,我们使用符号 M 来表示内核线程,使用符号 G 来表示 goroutine。在这个版本中,只有一个全局的 goroutine 队列,所有的内核线程都要从这个队列中取出 和放回goroutine。下图是一个包含两个内核线程,只有一个全局队列的例子。
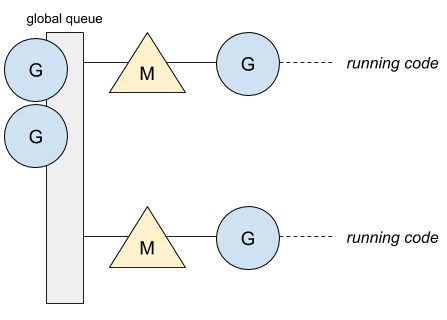
只有一个全局队列,导致无法保证一个 goroutine 会在同一个内核线程上调度。因此,一个 goroutine 会在不同的内核线程上调度,导致上下文切换较慢,非常影响性能。下面是一个阻塞通道的例子,用来说明这个问题:
goroutine G7 阻塞在 channel 上,等待接收一个消息。一旦接收到这个消息,G7 就被放到全局队列中。
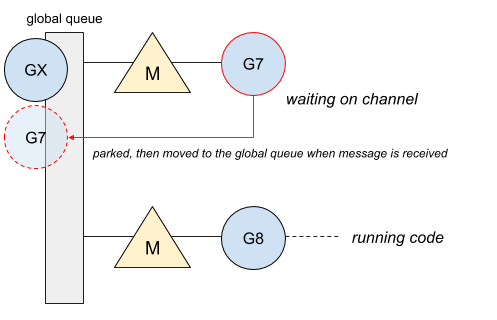
G7 被放到队列尾后,队列首的 GX 得到了被执行的机会,因此它被调度上第一个 M 上执行。此时,G8 也阻塞在 channel 上。
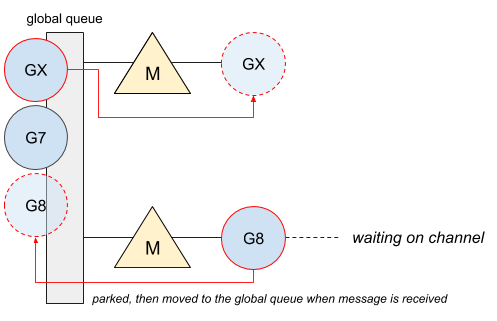
G7 重新得到了执行的机会,但是因为第一个 M 正在执行 GX,因此 G7 只能调度到第二个 M 上执行。这时候就发生了跨内核线程的上下文切换。
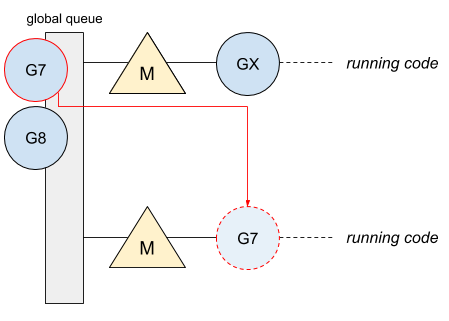
只有一个全局队列还带来了另外一个问题,因为从队列中获取 goroutine 必须要加锁,导致锁的争用非常频繁。尤其是在大量 goroutine 被调度的情况下,对性能的影响也会非常明显。
另外在 Scalable Go Scheduler Design Doc 这篇文章中还提到了另外两个问题。
- 所有的 M 都关联了内存缓存(mcache)和其他的缓存(栈空间),但实际上只有正在运行的 go 代码的 M 才需要 mcache(阻塞在系统调用的 M 不需要 mcache)。运行 go 代码的 M 和系统调用阻塞的 M 比例大概在 1:100,这就导致了大量的资源消耗(每个 mcache 会占用到 2M)以及 poor data locality(poor data locality找不到好的翻译,意思大概是内存缓存命中会很少,导致内存缓存无效,可参考这里:What does it mean that hash sets have poor data locality?)
-
激进的线程阻塞/解阻塞。因为系统调用导致工作线程经常被阻塞和解阻塞,这增加了很多的负担。
上面就是4个关于 go 1.0 中调度器的问题所在。Dmitry Vyukov 因此提出了新的调度算法,并在 go 1.1 中发布。
三、go 1.1 之后的调度器实现方案
针对在 1.0 中调度器实现的问题,go 1.1 在 M, G 的基础上,引入了新的角色 P(processor)。以下简单列出新的调度算法的改进点:
- 新角色 P 代替了 M 的一部分功能,M 的 mcache 现在属于 P 了,并且 P 的数量等于 GOMAXPROCS。M 要执行 G 的时候,就被调度绑定一个 P,然后去执行 G,这样对内存的占用就大大减少。
- 每个 P 都有自己的 goroutine 队列 runq,新的 G 就放到自己的 runq 上,满了之后再放到全局的 runq,优先执行自己的 runq。这样的设计大大减少了锁的争用,并且可以保证尽量少的在多个核心上传递 G。
- 当 G 执行网络操作和锁切换时,G 和 M 分离,M 通过调度执行新的 G。这样就可以保证用户在 G 中执行网络操作时不用考虑阻塞线程的问题。
- 当 M 因为执行系统调用阻塞或 cgo 运行一段时间后,sysmon 协程会将 P 和 M分离,由其他的 M 来结合 P 进行调度。这样 M 就不用因为阻塞而占用不必要的资源。
下面是一个比较易懂的图例:
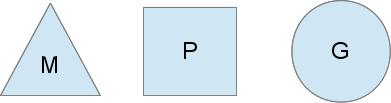
M 是内核线程,P 是调度的上下文,G 是 goroutine。
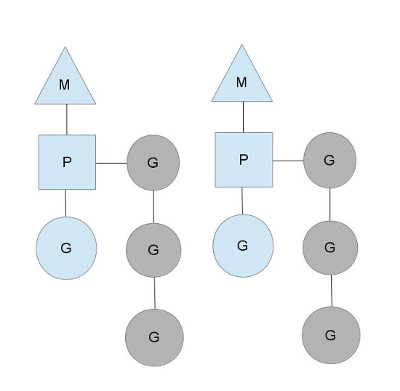
这里可以看到。M 绑定一个 P 来执行 G,灰色部分代表待执行的、只属于 P 的 goroutine 队列。
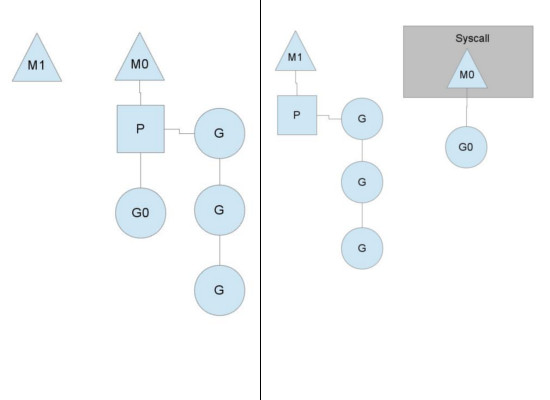
M0 线程因为执行 syscall 导致阻塞,因此调度算法将其和 P 分离,防止其占用 P 的资源,然后将 P 分给 M1 来执行剩下的 goroutine。
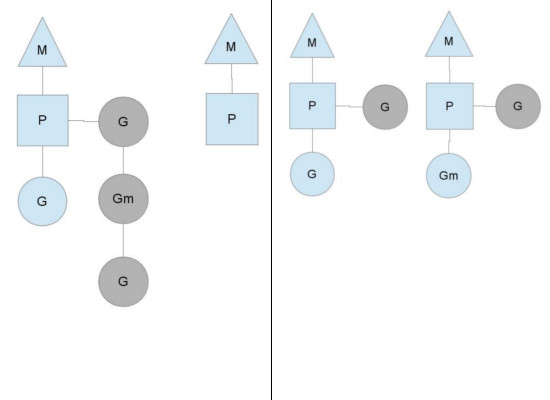
第二个 P 中的 goroutine 已经执行结束。因此从第一个 P 中“偷来”一部分的 goroutine 执行。
下面是一个比较详细的 GPM 模型示意图:
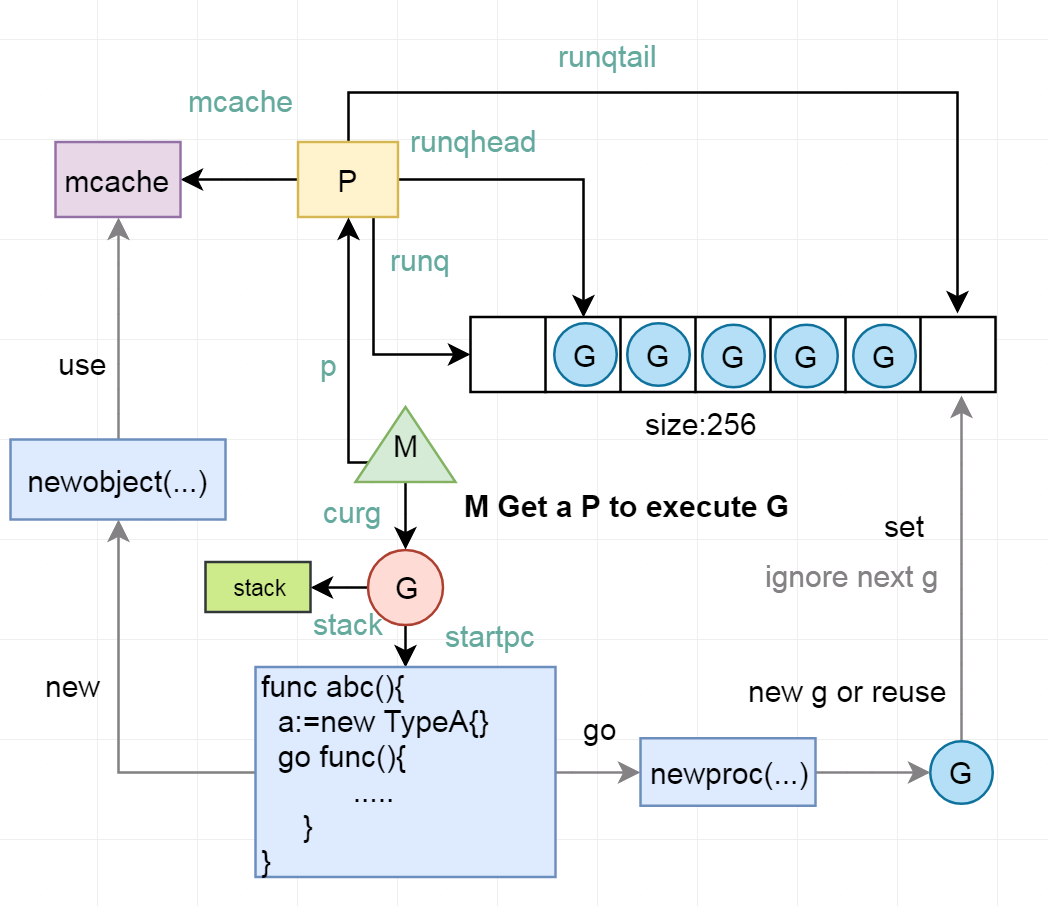
四、附加的参考资料
下面的一些图片是从腾讯技术团队分享的 PPT 中截取的,PPT 地址:深入浅出Golang Runtime
