理解service的角度
这篇文章不是关于如何使用kubernetes中的service,而是尝试整理我自己对service的看法,然后加深对service的理解。那么,我是从哪几个角度去看待service呢?
- service是服务的稳定性保证
- service是集群中的load balance
- 通过无selector的service去理解VIP(虚拟ip)
- service的设计,和不同实现方式的性能
service是服务的稳定性保证
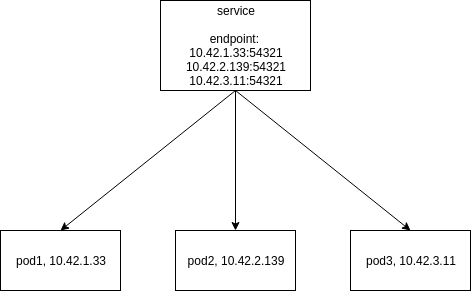
在k8s集群中,无状态的pod副本是可以随时删除、随时创建的,并且重新创建的pod不再保留旧的pod的任何信息,包括ip地址。在这样的情况下,前端应用如何使用后端的这些pod来提供服务就成了问题,因此k8s实现了service这样一个抽象的概念。对于有selector的service,它在被创建的时候会自动创建endpoint资源,这个endpoint中包含了所有的pod的ip和端口,并且在之后的pod的删除、创建中,这个endpoint中会立即更新相关pod的ip和端口信息。同时,service的ip地址是永远固定的,service和endpoint是一一对应的关系。这样,如果前端应用通过固定的service ip来访问pod提供的服务,那么就可以在endpoint中找到一个可用的pod的ip和端口,然后通过一些操作(这个在后面会整理)将数据包转发到指定的pod上即可。
# 你可以通过kubectl查看service和endpoint来加深理解
kubectl -n h2o describe svc h2o
Name: h2o
Namespace: h2o
Labels: app=h2o
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Service","metadata":{"annotations":{},"labels":{"app":"h2o"},"name":"h2o","namespace":"h2o"},"spec":{"clusterIP...
Selector: app=h2o
Type: ClusterIP
IP: None
Port: web 54321/TCP
TargetPort: 54321/TCP
Endpoints: 10.42.1.33:54321,10.42.2.139:54321
Session Affinity: None
Events: <none> kubectl -n h2o get endpoints h2o
NAME ENDPOINTS AGE
h2o 10.42.1.33:54321,10.42.2.139:54321 4h45m
service通过ip地址的固定来保证服务的稳定性。那为啥service就是可以固定不变的呢?这是因为service本身就是一个抽象的概念啊,它不是一个正在运行的进程,只是一条数据,也正因为如此,它的ip地址和端口号也是不存在的,这些都是存储在etcd中的一条数据。那么k8s是如何通过这样一个虚假的ip和端口将请求转发到真实存在的pod中呢?这就是后面要说的内容了。
service是集群中的load balance
在上一节说到,一个service会对应一个endpoint,这个endpoint中会保存所有当前匹配到的pod的ip和端口号。那么现在有一个http请求过来了,发现endpoint中有三个待选的pod,那么我们使用一定的方式比较公平的选择出一个pod,就轻松的达到了负载均衡的效果。
那么k8s中,load balance的策略是什么样的呢?因为不同的service实现方式使用的方法不同,这个内容会在后面整理。
通过无selector的service去理解VIP(虚拟ip)
在前面的内容中,service一直和endpoint、pod关联在一起,那么如果我们的service没有selector,就不会创建endpoint了,也不会关联pod。前面也提到了service是一个抽象的概念,其拥有的ip和port都是假的。其实这个叫做VIP(virtual ip)。那么,如何通过无selector的service来理解VIP呢?
在k8s中创建无selector service的时候,不会自动创建关联的endpoint,更不会去匹配pod了。但是这样的service仍然是拥有ip和port的。我们可以尝试一下:
svc-without-selector.yaml
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
ports:
- protocol: TCP
port: 8081
targetPort: 8081
kubectl apply -f svc-without-selector.yaml
查看一下这个svc的详情:
$ kubectl describe svc my-service
Name: my-service
Namespace: default
Labels: <none>
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Service","metadata":{"annotations":{},"name":"my-service","namespace":"default"},"spec":{"ports":[{"port":8081,...
Selector: <none>
Type: ClusterIP
IP: 10.43.12.208
Port: <unset> 8081/TCP
TargetPort: 8081/TCP
Endpoints: <none>
Session Affinity: None
Events: <none>
除了拥有ip和端口号,就什么都没有了。这就是说service为什么就是一条数据的原因,10.43.12.208也就是一个VIP。
对于无selector的service还有一个用处,就是让集群内部的应用可以稳定的访问到集群外部的服务。因为service是稳定的,那么集群内部都可以访问这个service,然后让这个service将请求转发到集群外。
这里我们可以手动创建一个endpoint,这个endpoint包含了集群外的两个http服务
apiVersion: v1
kind: Endpoints
metadata:
name: my-service
subsets:
- addresses:
- ip: 192.168.50.99
- ip: 192.168.50.201
ports:
- port: 8081
然后我们先检查一下service,发现endpoints已经更新了。
$ kubectl describe svc my-service
Name: my-service
Namespace: default
Labels: <none>
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Service","metadata":{"annotations":{},"name":"my-service","namespace":"default"},"spec":{"ports":[{"port":8081,...
Selector: <none>
Type: ClusterIP
IP: 10.43.12.208
Port: <unset> 8081/TCP
TargetPort: 8081/TCP
Endpoints: 192.168.50.201:8081,192.168.50.99:8081
Session Affinity: None
Events: <none>
我们在集群内部访问一下(使用kubectl exec到一个pod上):
$ wget my-service:8081 -q -O out | cat out
server 2
$ wget my-service:8081 -q -O out | cat out
server 1
$ wget my-service:8081 -q -O out | cat out
server 2
$ wget my-service:8081 -q -O out | cat out
server 1
service的设计,和不同实现方式的性能
service的设计是以提高性能为前提不断的演进的,这里是关于Service的设计讨论: DESIGN: Services v2。感兴趣的还可以看看k8s-release-v1.0的时候对service的描述: Service
service的设计中有4个角色: Pod、 Service、Ambassador、Portal
- Pod: k8s集群中的最小调度单位,包含一个或多个容器
- Service: 一组pod的集合,由标签选择器来关联
- Ambassador: 中文翻译是
大使,是一段可执行的逻辑,它负责实现客户端访问Service,然后将请求转发到一个对应的Pod上。这个Ambassador可以是一个云服务商的服务,也可以是一个单独的pod(比如haproxy),或者是每个节点都有的共享进程(kube-proxy)。 - Portal: 固定的ip:port对,客户端只要访问这个Portal,请求自然会被转发到Ambassador上,客户端不需要理解Ambassador的具体实现。
最初的设计中是有三种方案,
方案一: 每个服务一个ip,共享的Ambassador。这个ip就是上面说的Portal ip。将服务以及ip、端口广播给所有的kube-proxy实例。kube-proxy设置好iptables来“窃取”所有到Portal(ip,port)的请求,然后将这个请求转发到自己的某个端口上。这里kube-proxy扮演的是Ambassador角色,它会使用round-robin的方法来把请求均衡的分发到Service后面的Pod上。这个方案里,有以下的优点和缺点:
优点:
– 不会有端口冲突
– Service的ip和port都是固定的,方便做DNS A (forward) 和 PTR (reverse)和 SRV 记录。
– iptables可以放在root namespace,即使pods重启了也不需要更新iptables(这是因为iptables是负责将到service ip:port的流量转发到kube-proxy的一个端口上即可)。
– 不需要在pod上预先声明需要的Service。
缺点:
- kube-proxy是多租户的(需要为所有的service做流量转发)
- 从kube-proxy转发的流量的源ip不是真实的源ip,
- 需要为portal预留虚拟ip空间
- 需要master跟踪和检查所有的portal ip
- 当service数量级上千后可扩展性不高
方案二: 每个服务一个ip,私有的Ambassador。对每个pod来说,都有一个私有的的ambassador,这要求pod需要先声明它们想先访问那个服务(否则的话,对于集群中的每次Service的添加和删除,都需要kubelet或其他的root-namespace、true-root的用户代理变动到每个pod的namespace下。[iptables规则需要root用户]),这样才能在pod的命名空间下建立iptables规则。
优点:
- 不会有端口冲突
- Service的ip和port都是固定的,方便做DNS A (forward) 和 PTR (reverse)和 SRV 记录。
- 代理不是多租户的
- 从kube-proxy转发的流量的源ip是真实的源ip,
- 容易从方案一迁移
- 需要pod预先声明服务(结构良好)
缺点:
- iptables是配置在pod的namespace下,但是pod的命名空间重启了就必须重新运行一次
- 需要为portal预留虚拟ip空间
- 需要master跟踪和检查所有的portal ip
- 需要pod预先声明服务(目前还没实现)
方案三:localhost的portal,私有的ambassador
不同于给service分配ip,而是使用本地的端口号作为portal。
介绍完这三种方案后,就可以引入service最终的演进了: userspace->iptables->ipvs。
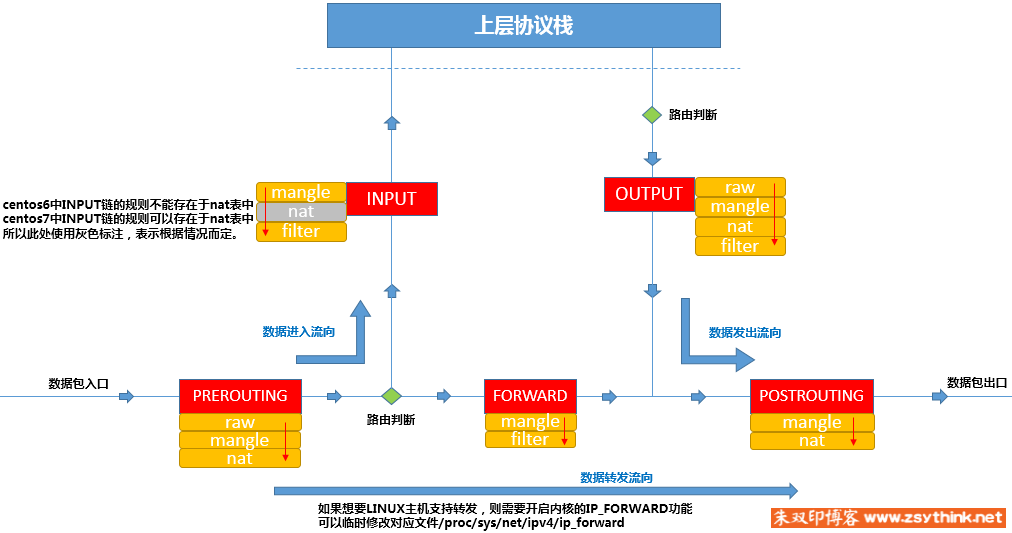
这里先放一张iptables的工作流程图,方便理解:
userspace模式
这里的userspace就是方案一的实现,在k8s 1.0的发布中正式启用。userspace的工作原理图如下:

这种模式,kube-proxy 会监视 Kubernetes master 对 Service 对象和 Endpoints 对象的添加和移除。 对每个 Service,它会在本地 Node 上打开一个端口(随机选择)。 任何连接到“代理端口”的请求,都会被代理到 Service 的backend Pods 中的某个上面(如 Endpoints 所报告的一样)。 使用哪个 backend Pod,是 kube-proxy 基于 SessionAffinity 来确定的。
最后,它安装 iptables 规则,捕获到达该 Service 的 clusterIP(是虚拟 IP)和 Port 的请求,并重定向到代理端口,代理端口再代理请求到 backend Pod。默认情况下,用户空间模式下的kube-proxy通过round-robin选择后端。
这里有一个问题在于,client访问service的clusterIP时,iptables会把流量转发到kube-proxy的某个端口上,这样的话,每次转发都有一个内核态到用户态的转换。
iptables模式

这种模式,kube-proxy 会监视 Kubernetes 控制节点对 Service 对象和 Endpoints 对象的添加和移除。 对每个 Service,它会安装 iptables 规则,从而捕获到达该 Service 的 clusterIP 和端口的请求,进而将请求重定向到 Service 的一组 backend 中的某个上面。 对于每个 Endpoints 对象,它也会安装 iptables 规则,这个规则会选择一个 backend 组合。
默认的策略是,kube-proxy 在 iptables 模式下随机选择一个 backend。类似于这样
iptables -t nat -A PREROUTING -p tcp -d 15.45.23.67 --dport 80 -j DNAT --to-destination 192.168.1.1-192.168.1.10
使用 iptables 处理流量具有较低的系统开销,因为流量由 Linux netfilter 处理,而无需在用户空间和内核空间之间切换。 这种方法也可能更可靠。
如果 kube-proxy 在 iptable s模式下运行,并且所选的第一个 Pod 没有响应,则连接失败。 这与用户空间模式不同:在这种情况下,kube-proxy 将检测到与第一个 Pod 的连接已失败,并会自动使用其他后端 Pod 重试。
您可以使用 Pod readiness 探测器 验证后端 Pod 可以正常工作,以便 iptables 模式下的 kube-proxy 仅看到测试正常的后端。 这样做意味着您避免将流量通过 kube-proxy 发送到已知已失败的Pod。
ipvs模式
ipvs是在Kubernetes v1.11正式可用的。ipvs也是依赖于iptables的,但是它的性能更高。

在ipvs模式下,kube-proxy监视Kubernetes服务和端点,调用netlink接口相应地创建IPVS规则,并定期将IPVS规则与Kubernetes服务和端点同步。该控制循环可确保IPVS状态与所需状态匹配。访问服务时,IPVS 将流量定向到后端Pod之一。
IPVS代理模式基于类似于iptables模式的netfilter挂钩函数,但是使用哈希表作为基础数据结构,并且在内核空间中工作。 这意味着,与iptables模式下的 kube-proxy 相比,IPVS 模式下的 kube-proxy 重定向通信的延迟要短,并且在同步代理规则时具有更好的性能。与其他代理模式相比,IPVS 模式还支持更高的网络流量吞吐量。
IPVS提供了更多选项来平衡后端Pod的流量。 这些是:
- rr: round-robin
- lc: least connection (smallest number of open connections)
- dh: destination hashing
- sh: source hashing
- sed: shortest expected delay
- nq: never queue
注意:
要在IPVS模式下运行kube-proxy,必须在启动kube-proxy之前使IPVS Linux在节点上可用。当 kube-proxy 以 IPVS 代理模式启动时,它将验证 IPVS 内核模块是否可用。 如果未检测到 IPVS 内核模块,则 kube-proxy 将退回到以 iptables 代理模式运行。
ipvs在同步规则、网络带宽、cpu/内存消耗上都明显优于iptables,关于具体的性能数据可以看这篇文章: 华为云在 K8S 大规模场景下的 Service 性能优化实践。ipvs的详细介绍可以看这篇文章:ipvs 基本介绍。ipvs和iptables的对比:kube-proxy 模式对比:iptables 还是 IPVS?